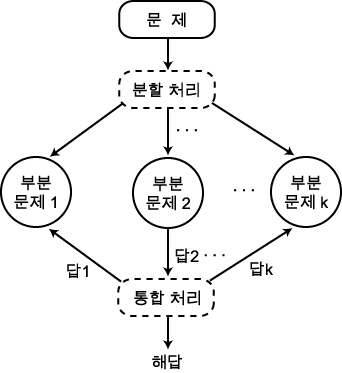
3. 동적 계획법 (dynamic programming)
재귀적인 기법은 문제를 간단히 부분 문제로 분할할 수 있고, 부분 문제의 크기의 합을 적게 유지할 수 있는 경우에 유효하다. 그러나, 크기가 n인 문제를 단순히 분할해서 각 부분 문제의 크기가 균형이 맞지 않는 문제로 분할되었을 때에는 재귀적 알고리즘의 복잡도는 아마 지수 함수적으로 증가할 것이다. 이런 경우에는 「동적 계획법」이라는 기법을 이용하면 효율좋은 알고리즘을 설계할 수 있다.
문제를 크기가 적은 부분 문제로 분할한 뒤 부분 문제에 대한 답을 구하기 위해 같은 부분 문제를 몇 번이고 반복해서 해결할 필요가 있는 경우가 있다. 그 때에는 한번 해결한 부분 문제의 해답을 「표」에 기억해 두었다가 필요할 때에 그 표를 참조하게 하면 새로 계산하는데 걸리는 시간을 절약할 수 있게 되어 효율이 좋은 알고리즘을 얻을 수가 있다.
이와 같이 경우에 따라서는 언젠가는 해결하게 될 모든 부분 문제의 해답을 표로 해두는 것이 프로그램을 작성하기 쉬운 경우도 있다. 어떤 부분 문제가 실제로 전체의 문제 해결 과정에서 필요하게 되는지 어떤지는 생각하지 않고 일단 표를 작성하는데, 이와 같이 주어진 문제를 해결하기 위해 부분 문제에 대한 답을 표에 기입하는 기법을 동적 계획법 (dynamic programming) 이라고 한다. 동적계획법이라는 이름은 제어 이론에서 나온 것이다.
본질적으로는 동적 계획법은 모든 부분 문제에 대한 답을 계산하는데, 계산은 크기가 작은 부분 문제로부터 보다 큰 부분 문제로 답을 표에 기록하면서 나아간다. 동적 계획법의 장점은 한번 어떤 부분 문제가 해결되면 답을 기억해 둠으로써 결코 두 번 다시 계산되지 않는다는 것이다. 이 기법은 간단히 예를 보면 쉽게 이해할 수 있을 것이다.
먼저 다음과 같은 n 개의 행렬을 곱하는 문제를 생각하기로 한다. 단, 각 행렬 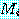 의 크기는
의 크기는 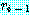 행,
행, 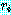 열로 한다.
열로 한다.
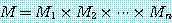
행렬을 곱하는데 어떤 알고리즘을 이용하더라도 행렬이 곱해지는 순서가 M 을 계산하는데 필요한 연산의 총수에 영향을 미친다.
연산 순서와 연산하는 횟수와의 관계를 보기 위해 다음과 같은 실제적인 행렬 곱셈을 예로 들어보기로 하자.
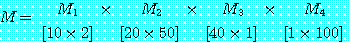
괄호속에 있는 수는 각 행렬  의 치수를 나타낸다. 일반적인 방법을 이용하면 p × q차 행렬과 q × r 차 행렬의 곱셈은 p × q × r 번의 연산을 필요로 하므로, M 을
의 치수를 나타낸다. 일반적인 방법을 이용하면 p × q차 행렬과 q × r 차 행렬의 곱셈은 p × q × r 번의 연산을 필요로 하므로, M 을 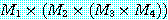 의 순으로 계산하면 125000 번의 연산이 필요하지만
의 순으로 계산하면 125000 번의 연산이 필요하지만 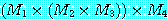 순으로 계산하면 2200 번의 연산이면 된다. 이들 연산수를 살펴보기 위해 다음과 같은 동적 계획법을 이용하면 된다.
순으로 계산하면 2200 번의 연산이면 된다. 이들 연산수를 살펴보기 위해 다음과 같은 동적 계획법을 이용하면 된다.
행렬의 곱셈에 필요한 연산수를 최소화하기 위해서는 n 개의 행렬을 곱하는 순서를 모두 체크하면 되지만 이것은 막대한 시간과 노력을 필요로 한다. 그러나, 동적 계획법을 이용하면 복잡도가 O(n3) 의알고리즘을 얻을 수가 있는데, 행렬의 곱셈을 하는데 연산수가 가장 적은 방법을 찾기 위해서는 동적 계획법을 어떻게 이용하는지를 설명하기로 한다.
mi, j가 mi × Mi+1 × … × Mj 를 계산하는데 걸리는 시간 중에서 가장 적은 시간이라 하고, 이것을 식으로 나타내면 다음과 같다.
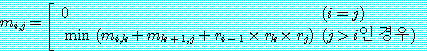
위의 식에서 첫 번째 항인 mi, k 는 M' = Mi × Mi+1 × … × Mk 를 계산하는데 걸리는 시간 중에서 가장 적은 시간을 나타내고, 두 번째 항인 mk+1, j 는 M″ = Mk+1 × Mk+2 × … × Mj 를 계산하는데 걸리는 시간 중에서 가장 적은 시간을 나타낸다. 단, M′ 는 ri-1 × rk 차 행렬, M″ 는 rk × rj 차 행렬이다. mi, j 는 모든 k(i ≤ k ≤ j - 1) 에 대해 이들 세 항을 합한 값이 가장 적은 값이라는 것을 나타낸다.
이 동적 계획법에 의한 방법에서는 첨자의 값의 차가 적은 순으로 mi, j 를 계산해 간다. 즉, 모든 i 에 대해 mi, i 를 계산하는 것에서부터 시작해서 mi, i+1 과 mi, i+2 순으로 계산한다.
M = M1 × M2 × M3 × M4 를 계산하는데 이 알고리즘을 적용하기로 한다. 단, r0, r1, r2, r3, r4는 10, 20, 50, 1, 100 이고 mi, j 의 값을 계산한 결과는 다음과 같다. 따라서, 곱셈을 하는데 필요한 최소의 연산수는 2200 이 된다.
|
m1, 1 = 0 |
m2, 2 = 0 |
m3, 3 = 0 |
m4, 4 = 0 |
|
m1, 2 = 10000 |
m2, 3 = 1000 |
m3, 4 = 5000 |
|
|
m1, 3 = 1200 |
m2, 4 = 3000 |
|
|
|
m1, 4 = 2200 |
|
|
|
동적 계획법에 대한 또하나의 예로서 다각형을 삼각형으로 분할하는 최소삼각형 분할 문제를 생각하기로 한다.
삼각형 분할 문제란 다각형의 정점과 각 정점간에 거리가 주어져 있을 때, 서로 인접하지 않는 두 정점 사이에 새로 선(arc)을 그어서 다각형 전체를 삼각형으로 분할하는 것이다. 삼각형 분할 문제 중에서 삼각형으로 분할하기 위해 정점과 정점 사이에 그어진 선의 길이의 합을 최소화하는 문제를 최소삼각형으로 분할하기 위해 정점과 정점 사이에 그어진 선의 길이의 합을 최소화하는 문제를 최소삼각형 분할 문제라고 한다.
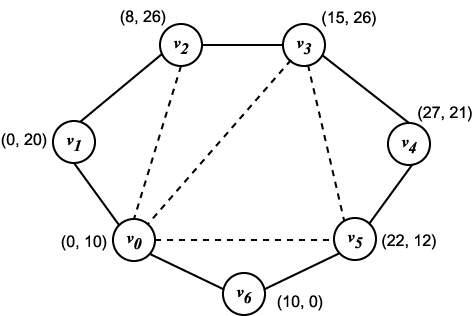
그림 7 7 각형과 삼각형 분할의 예

그림 8 삼각형 분할의 예
그림 7 에 7 각형과 각 정점에 대한 (x, y) 좌표를 나타내는데 거리 함수는 일반적인 유클리드 거리로 한다. 그림 7 에서 삼각형 분할의 한 예를 점선으로 나타냈지만 예를들면 그림 8과 같은 삼각형 분할이 있으므로 이것은 최소삼각형 분할이 아니다. 그림 7과 같은 분할의 코스트는 변 (1, 3), (1, 4), (1, 6), (4, 6) 의 길이의 합계
즉, 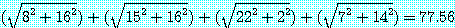 이고, 그림 8 과 같은 분할 코스트는 변 (1, 3), (1, 4), (1, 5), (1, 6) 의 길이의 합계 즉,
이고, 그림 8 과 같은 분할 코스트는 변 (1, 3), (1, 4), (1, 5), (1, 6) 의 길이의 합계 즉, 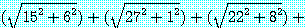
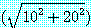 =45.16이다.
=45.16이다.
이 삼각형 분할 문제에 동적 계획법을 적용하기 전에 삼각형 분할이 가지는 두 가지 성질을 정리해 두고, 그들 성질을 알고리즘 설계에 이용하기로 한다. 다각형에는 시계 방향으로 n 개의 정점 v1, v2, …, vn 이 있다고 한다.
[성질 1]
세 정점 이상으로 구성된 다각형을 삼각형 분할했을 때 다각형의 변과 접해 있는 두 정점은 반드시 하나 이상의 선과 접해 있다. 만일 vi 과 vi-1 이 모두 어떠한 선과도 접하지 않는다고 하면, 변 (vi, vi-1) 이 에워싸고 있는 영역에는 변(vi-1, vi) 과 (vi+1, vi+2) 외에 하나 이상의 변이 포함된다. 이렇게 되면 이 영역은 삼각형이 되지 않는다.
[성질 2]
어떤 삼각형 분할에서 (vi, vj) 를 선이라고 하면, (vi, vk) 와 (vk, vj) 가 모두 다각형의 변 혹은 선이 되는 vk 가 여러 개 존재한다. 그렇지 않으면 (vi, vj) 가 삼각형이 아닌 영역을 에워싸고 있는 것이 된다.
다음은 앞의 두 개의 성질을 이용하여 최소삼각형 분할 문제를 해결하는 알고리즘을 설명하기로 한다.
최소삼각형 분할을 하기 위해 우선 인접하는 두 정점 v0 과 v1을 선택한다. 위에 기술한 두 성질은 임의의 삼각형 분할에서 성립하므로 최소의 삼각형 분할에서도 성립한다. 따라서 (v1, vk) 와 (vk, v0) 가 모두 삼각형 분할에서의 선 혹은 변이되는 정점 vk 가 존재한다. 이 때, 여러 개의 k 가 존재하면 어느 경우에 어느 정도 좋은 삼각형 분할을 할 수 있는지를 생각해야 하는데 n 개의 정점을 가진 다각형이라면 모두 (n - 2) 개의 선택이 가능하다.
어느 k 를 택하더라도 그로 인해 생기는 부분 문제는 많아야 두 개인데, 그들은 선택한 선의 양쪽 끝에 있는 두 정점을 잇는 원래의 다각형의 변에 의해 구성되는 두 개의 다각형에 대응한다. 예를들면 정점 v3 를 선택하면 그림 9에 나타내는 두 개의 부분 문제가 생긴다.
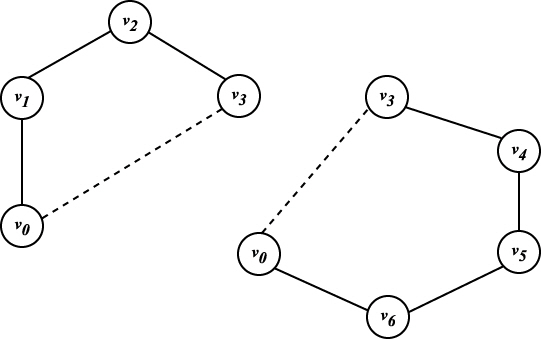
그림 9 v3 을 택했을 때의 부분 문제
다음은 그림 9(a), (b) 의 다각형에 대한 최소삼각형 분할을 해야 하는데, 그를 위해서는 또 인접하는 두 정점에서 나오는 선을 모두 생각해야 한다고 여겨진다. 예를들면 그림 9(b) 를 해결하기 위해서 선 (v0, v3) 과 같은 부분 문제의 선과 그외의 정점으로 삼각형을 만들어야 한다. 가령 v4 를 선택했다고 하면 삼각형 (v0, v3, v4) 와 부분 문제 (v0, v4, v5, v6) 이 생기고, 이 부분 문제 중에서 원래의 다각형의 선은 하나 뿐이다. 한편, v4 가 아니라 v5 를 선택하면 부분 문제 (v3, v4, v5) 와 (v0, v5, v6) 이 생기는데 각 부분 문제에 대한 선은 (v3, v5) 와 (v0, v5) 뿐이다.
일반적으로 정점 vi 에서 시작해서 시계 방향으로 s 개의 정점 vi, vi+1, …, vi+s-1 로 구성되는 다각형에 대한 최소삼각형 분할을 구하는 문제를 「정점 vi 에서 시작하는 크기가 s 인 부분 문제」라고 하고, 이후 이를 Si, s 라고 표현하기로 한다. 예를들면 그림 9 (a) 는 S0, 4 이고 그림 9(b) 는 S3, 5 이다. Si, s 를 해결하기 위해서는 다음의 세 경우를 생각할 필요가 있다.
(1) 정점 vi+s-2 를 선택해서 선 (vi, vi+s-1) 및 (vi, vi+s-2) 와 변 (vi+s-2, vi+s-1) 로 삼각형을 구성하여 부분 문제 Si, s-1 를 해결한다.
(2) 정점 vi+1 을 선택해서 선 (vi, vi+s-1), (vi+1, vi+s-1) 과 변 (vi, vi+1) 로 삼각형을 구성하여 부분 문제 Si+1, s-1 를 해결한다.
(3) 정점 vi+k(2 ≤ k ≤ s - 3) 를 선택해서 선 (vi, vi+k), (vi+k, vi+s-1), (vi, vi+s-1) 로 삼각형을 구성하여 부분 문제 Si,k+1 와 Si+k, s-k 를 해결한다.
크기가 3 이하인 부분 문제를 해결하기 위해서는 아무 것도 하지 않아도 되므로, (1) ~ (3) 을 이용해서 어떤 k(1 ≤ k ≤ s - 2) 를 택해서 부분 문제 Si, k+1 와 Si+k, s-k 를 해결하면 되는데, 부분 문제의 분할을 그림 10 에 나타낸다.
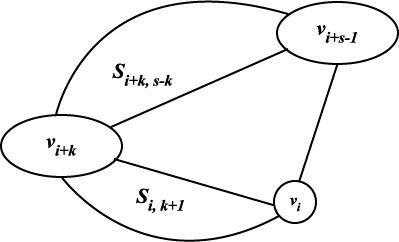
그림 10 Si, s 를 부분 문제로 분할
크기가 4 이상인 부분 문제를 해결하기 위해서는 위의 규칙을 이용해서 얻어지는 재귀적인 알고리즘을 사용하기로 하자. 이 때, 크기가 s 이상인 부분 문제를 해결하기 위한 재귀적 호출수만을 세면 모두 3s-4 번이라는 것을 나타낼 수 있으므로, 해결해야 할 부분 문제의 수는 s 를 지수로 한 것이 된다. 문제를 분할한 후의 문제의 크기는 이 재귀적인 절차를 해결하는데 필요한 모든 스텝수와 같은데, 주어진 다각형의 정점수가 n 이므로 문제의 크기는 n 의 지수승이 된다.
그러나, 원래의 문제 이외에는 해결해야 할 부분 문제는 n(n - 4) 종류밖에 없다는 것을 알고 있기 때문에 이 해석이 어딘지 이상하다는 것은 금방 알 수 있을 것이다. 그 부분 문제라는 것은 Si, s(0 ≤ i < n, 4 ≤ s(n) 이므로 재귀적인 절차에서는 같은 부분 문제를 여러 번 해결한다는 것이 분명하다. 예를들면 그림 6 ~ 7 에서 선 (v0, v3) 을 선택하고 그림 9(b) 의 부분 문제에서 v4 를 선택했다고 하면 부분 문제 S4, 4를 해결해야 한다. 그러나, 처음에 변(v0, v4) 를 선택했을 때와 처음에 선(v1, v4) 를 선택해서 부분 문제 S4, 5 를 해결할 때에 v1 과 v4 를 정점으로 하는 삼각형을 완성시키기 위해서 v0 을 선택해도 역시 같은 부분 문제 v4, 4 를 해결하게 된다.
이로부터 삼각형 분할 문제를 해결할 수 있는 효율이 좋은 방법을 얻을 수가 있다. 모든 i 와 s 에 대해 Si, s 를 삼각형 분할하는데 걸리는 시간 (이후, 이것을 Ci, s 로 표현한다) 을 계산하는 표를 만드는 것으로, 이 때 어떤 문제의 해답도 보다 적은 문제의 해답에만 의존하므로 이 표를 크기순으로 메워가면 된다. 즉, 크기 S( = 4, 5, …, n - 1) 에 대해 모든 정점 i 에 대한 문제 Si, s) 의 최소값을 써넣는다. 크기 0 ≤ s < 4 인 문제도 포함해 두면 편리하지만 s < 4일 때 Si, s 의 코스트가 0 이라는 것을 잊어서는 안된다.
여기서 부분 문제를 정하기 위한 Ci, s(S ≥ 4) 를 계산하는 식은 다음과 같다.
Ci, s = min{Ci, k+1 + Ci+k, s-k + D(vi, vi+k) + D(vi +k, vi+s-1)}
여기서 D(vp, vq) 는 정점 vp 와 vq 가 다각형상에서 인접하지 않을 때는 이 두 정점을 연결하는 선의 실이를 나타내고 vp 와 vq 가 인접하고 있을 때는 0 으로 한다.
그림 7 에 있는 다각형과 거리를 토대로 하여 0 ≤ i < 6, 4 ≤ s < 6 에 대한 Ci, s 를 갖는 표를 다음에 나타냈는데, s < 3 인 행에 있는 값은 모두 0 이다. i = 0 인 열과 s = 7 인 행에 C0, 7 의 값이 들어 있는데 이 값은 같은 행에 있는 다른 값과 마찬가지로 다각형 전체의 삼각형 분할을 나타내고 있다. 왜냐하면, 변(v0, v6) 을 보다 큰 다각형의 변이라고 생각해서 그림 7 에 있는 다각형은 큰 다각형의 부분 문제라고 생각하면 된다. 큰 다각형은 v7 에서 v1 까지의 사이에 여러 개의 정점열을 갖고 있을 것이다. s = 7 인 행은 모두 C0, 7 과 같은 값을 갖는다.
|
7 |
C0, 7 = 75.43 |
|
|
|
|
|
|
|
6 |
C0, 6 = 53.34 |
C1, 6 = 55.22 |
C2, 6 = 57.54 |
C3, 6 = 59.67 |
C4, 6 = 59.78 |
C5, 6 = 59.78 |
C6, 6 = 63.61 |
|
5 |
C0, 5 = 37.54 |
C1, 5 = 31.81 |
C2, 5 = 35.45 |
C3, 5 = 37.74 |
C4, 5 = 45.50 |
C5, 5 = 39.98 |
C6, 5 = 38.09 |
|
4 |
C0, 4 = 16.16 |
C1, 4 = 16.16 |
C2, 4 = 15.65 |
C3, 4 = 15.65 |
C4, 4 = 22.09 |
C5, 4 = 22.09 |
C6, 4 = 17.8 |
|
s i=0 1 2 3 4 5 6 | |||||||
예를 들면 i = 6 인 열과 S = 5 인 행의 값 38.09 를 계산하는 방법을 설명하기로 하자. Ci, s 의 계산식에 의해 이 값 C6, 5 는 k = 1, 2, 3 에 대응하는 세 개의 합중에서 가장 적은 값이다. 세 개의 합이라는 것은,
C6, 2 + C0, 4 + D(v6, v0) + D(v0, v3)
C6, 3 + C1, 3 + D(v6, v1) + D(v1, v3)
C6, 4 + C2, 2 + D(v6, v2) + D(v2, v3)
이다. 계산에 필요한 거리는 정점의 좌표로부터 다음과 같이 구해진다.
D(v2, v3) = D(v6, v0) = 0
(이들은 다각형의 변으로 선은 아니므로 코스트는 0 이다).
D(v6, v2) = 26.08
D(v1, v3) = 16.16
D(v6, v1) = 22.36
D(v0, v3) = 21.93
위의 세 가지의 합은 각각 38.09, 38.52, 43.97 이므로 부분 문제 S6, 5 의 최소값은 38.09 가 되었다. 또, 제일 위에 있는 것이 최소값이므로 이 값을 얻기 위해서는 부분 문제 S6, 2 와 S0, 4 를 사용해야 한다는 것 즉, 선 (v0, v3) 을 선택해서 S6, 4 에는 선 (v1, v3) 을 선택하는 것이 좋다.
위의 표는 최소삼각형 분할의 코스트를 나타내고 있지만 이것으로 삼각형 분할의 방법 자체를 금방 알 수 있는 것은 아니다. 각 Ci, s 에 대해 위의 식에서 최소값을 만든 k 의 값을 알 필요가 있는데, 이것을 알면 답속에 선 (vi, vi+k) 와 (vi+k, vi+s-1) 이 포함된다는 것을 알 수 있다(단, k = 1 과 k = s - 2 일 때는 한쪽이 선이 되지 않는다). 이외의 선은 Si, k+1 과 Si+k, s-k 의 답에서 생기는데 표에 있는 각 요소를 계산할 때에 최적해의 근거가 되는 k 의 값도 기록해 두면 도움이 된다.
그림 6 ~ 7 에 있는 다각형에 대한 최소삼각형 분할을 그림 6 ~ 11 에 나타낸다.
앞의 표에서 그림 6 ~ 7 의 문제 전체의 답을 나타내고 있는 요소 C0, 7 은 k = 5 일 때에 생기므로 문제 S0, 7`은 S0, 6 과 S5, 2 로 나눠진다. S0, 6 은 6 개의 정점 v0, v1, …, v5 를 가진 문제이지만 S5, 2 는 코스트 0 인 명백한 문제이다. 따라서 코스트 22.09 인 선 (v0, v5) 를 사용하게 되어 다음은 S0, 6 을 해결해야 한다.
C0, 6 의 최소값은 k = 2 인 항에서 생기므로 문제 S0, 6 이 S0, 3 과 S2, 4 로 나누어진다. S0, 3 은 삼각형 v0, v1, v2 이고 S2, 4 는 사각형 v2, v3, v4, v5 이다. 여기서, S0, 3 은 해결할 필요는 없지만 S2, 4 는 해결해야 하고 여기서 선 (v0, v2) 와 (v2, v5) 의 코스트 17.89 와 19.08 이 더해진다. C2, 4 의 최소값은 k = 1 일 때에 생기므로 부분 문제 S2, 2 는 S3, 3 이 얻어지지만 어느 쪽도 정점수가 3 이하이므로 코스트는 0 이 된다. 여기서 선 (v3, v5) 가 도입되는데 이 선의 코스트는 15.65 이다.
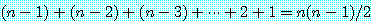
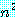 ) 이 된다.
) 이 된다.
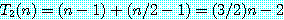
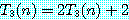
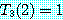
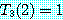
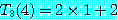
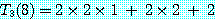
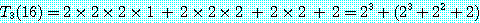
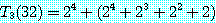
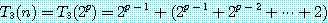
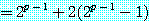


 debugging.doc
debugging.doc