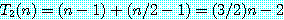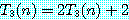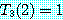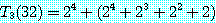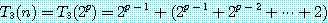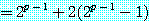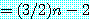6. 근사해법 (approximation algorithm)
해결하려는 문제마다 크기가 다르므로 한마디로는 말할 수 없지만 복잡도가 O(n)이나 O(n log n) 또는 O(n3) 등과 같이 문제의 크기 n 에 대해 제곱승 또는 세제곱승 정도의 복잡도를 가진 알고리즘이라면 실제로 사용가능하다. 제5장까지 설명한 알고리즘은 이 범위에 속하는 「효율적인」알고리즘이었으나 문제에 따라서는 이러한 효율적인 알고리즘이 없는 경우도 흔히 있다.
이와 같이 효율적인 알고리즘이 발견되지 않은 「어려운」문제에 대해서 이론적인 수법을 이용하여 그 어려운 정도를 알아내려는 연구가 오래전부터 많이 행해졌다. 효율적인 알고리즘을 발견해 내지 못하기 때문에, 그 문제에 대해서는 효율적인 알고리즘이 존재하지 않는다는 것을 증명하는 연구를 하는 것은 당연하다.
이러한 이론적인 연구를 복잡도 이론 (complexity theory) 이라고 한다. 알고리즘에 대한 연구는 복잡도 이론에 관한 추상적인 것과 지금까지 설명한 알고리즘 개발을 목표로한 실제적이고 구체적인 것으로 나눌 수 있다.
복잡도 이론에서는 문제를 그 어려운 정도에 따라 분류하는 것이 주요 연구 테마이다. 여기서는 그 분류에 관해서 알려져 있는 사실과 해결되지 않는 문제점을 간단히 소개하기로 한다. 이들 연구의 성과는 효율적인 알고리즘을 설계한다는 목적과는 직접 관계가 없다. 그러나 본질적으로 어려운 문제에 대해서 효율적인 알고리즘을 개발하려는 필요없는 노력을 하지 않게 하고 다른 방향에서 문제를 해결하는 기회를 제공한다는 소극적인 효용이 있다.
복잡도 이론에서는 복잡도가 문제의 크기 n 의 다항식으로 평가되는 알고리즘을 효율적 (efficient) 알고리즘이라고 하고, 반대로 n 의 다항식이 아닌 지수 함수의 형태로 평가되는 알고리즘의 비효율적 (non-efficient) 알고리즘이라고 한다. 다항식과 지수 함수의 사이에 위치하는 알고리즘 (O(nlog n) 과 같은 북잡도를 가진 알고리즘) 에 대해서는 아직 충분히 연구가 되고 있지 않는 실정이다.
효율적인 알고리즘이 존재하는 문제를 쉬운 문제 (tractable problem) 라고 하고 효율적인 알고리즘이 존재하지 않는 문제를 어려운 문제 (intractable problem) 라고 한다.
쉬운 문제와 어려운 문제를 나누는 기준은 모든 경우를 생각해야 하는 것에 있다. 즉 모든 경우를 생각해야 하는 문제를 어려운 문제라고 하고 그렇지 않은 문제를 쉬운 문제라고 한다. 문제가 쉽다는 것을 증명하기 위해서는 효율적인 알고리즘을 개발하면 그것으로 증명이 된다. 반대로 어렵다는 것을 증명하기 위해서는 어떤 알고리즘을 이용하더라도 그 문제를 효율적으로 해결할 수 없다는 것을 증명할 필요가 있기 때문에 그다지 간단하지는 않다. 어렵다는 것이 증명되어 있는 문제는 몇 가지 있지만 그 수는 많지 않다. 이와 같이 다항식 시간의 알고리즘이 존재하지 않는다는 것이 알려져 있는 문제는 그 문제에 대한 효율적인 알고리즘을 개발하려고 할 때 필요없는 노력을 하지 않고 처음부터 포기할 수 있는 결단을 내리는데 도움이 되므로 이러한 의미에서는 다루기 쉽다.
그러나, 이보다 다루기 어려운 것은 쉬운지 어려운지가 (지금까지) 알려져 있지 않는 문제이다. 이들 문제에는 효율적인 알고리즘이 알려져 있지 않을 뿐만 아니라 다항식 시간의 알고리즘이 존재하지 않는다는 것도 증명되어 있지 않다. 그리고 실제로도 어려운 것을 하려고 하면 금방 이들 문제에 부딪힌다고 해도 과언이 아닐 정도로 이런 문제는 매우 많이 존재한다. 이와 같은 문제들을 NP 완전 문제 (NP-complete problem) 라고 한다.
일반적인 알고리즘에서는 각 스텝에서 어떤 조작을 한다는 것이 명확하게 정해져서 기술되어 있으므로 데이터를 입력하면 어떤 조작을 어떤 순서로 한다는 것을 알 수 있다. 이러한 알고리즘을 특히 결정성 알고리즘 (deterministic algorithm) 이라고 부른다. 결정성 알고리즘에 의해 다항식 시간에 해결할 수 있는 문제를 모두 클래스 P(class P) 에 속하는 문제라고 한다.
이에 대해서 NP 라고 하는 것은 비결정성 알고리즘 (nondeterministic algorithm) 을 이용하면 다항식 시간에 해결할 수 있는 것을 의미한다. 비결정성 알고리즘이란 개개의 스텝에서 취할 수 있는 경로가 여러 개로 나눠져 있어서 그 중에서 적당한 경로를 택해서 실행해 나가는 것이다. 경로를 택한다고 하더라도 if 문에 의한 조건 분기와 같이 어느 경로를 선택할 것인가에 대한 정보가 주어져 있는 것이 아니다. 아무튼 어느 경로든지 하나의 경로를 택해서 앞으로 실행해 나가는 수밖에 없다. 그리고 이들 경로 중 가장 적합한 경로를 잘 택했을 때에 다항식 시간으로 답을 찾아내는 문제의 집합이 클래스 NP (class NP) 이다.
그러나, 가장 좋은 경로를 택하면 다항식 시간으로 해결할 수 있다고는 하더라도 그런 경로를 잘 택할 수 있다는 보장도 없다. 어느 경로를 택하면 좋을지를 알 수 있는 방법이 없으므로 잘못된 경로를 택하면 오랜 시간을 필요로 할지도 모르고 답을 찾아내지 못할지도 모른다.
즉 정말도 다항식 시간에 해결할 수 있는 것은 어느 경로를 택하면 좋은지를 알 수 있는 것은 「신 (god)」뿐이다. 신이 아닌 사람이나 컴퓨터로서는 어느 경로를 택해서 앞으로 실행해 나가서 막히면 되돌아오는 등 모든 경로의 계산을 병행해서 나아가는 등의 수단을 사용할 수밖에 없다. 즉, 비결정성 알고리즘의 동작을 일반적인 결정성 알고리즘으로 모방해서 해결하는 셈이다.
이렇게 모방함으로써 복잡도의 정도도 바뀐다. 예를들면, 각 스텝에서 두 개씩 분기한다고 하면 원래의 비결정성 알고리즘인 경우 n 스텝에 해결할 수 있는 문제도 O(2n) 정도의 복잡도를 필요로 한다고 예상할 수 있다.
이상의 설명으로 크래스 NP 에 속하는 문제를 실제로 다항식 시간에 해결할 수 있다고 단언할 수 없다는 것은 이해할 수 있을 것이다.
결정성 알고리즘에 의해 다항식 시간에 해결할 수 있는 문제는 비결정성 알고리즘에 의해서도 다항식 시간에 해결할 수 있으므로 P ⊆ NP 가 성립한다. 그러나 NP ⊆ P 즉 NP 에 속하는 어떤 문제라도 다항식 시간에 해결할 수 있다면 P = NP 가 성립한다. 이것이 사실인지 아니면 P = NP 즉, 다항식시간에 해결할 수 있는 알고리즘이 존재하지 않는 문제가 NP 속에 있는지는 대문제이다. 이 문제는 P = NP 문제라고 불리는 문제로서 컴퓨터 과학 분야에서는 최대의 과제 중 하나이다.
많은 연구자는 P ≠ NP 즉, NP 속에는 효율적으로 해결할 수 없는 문제가 있다고 믿고 있다. 이것은 효율적인 알고리즘이 존재할 것같지 않은 문제가 NP 속에 많이 존재한다는 점과 비결정성을 그렇게 간단하게 결정성 알고리즘으로 바꿀 수 있다고는 생각하지 않는다는 등의 이유 때문이다. 그러나 아직 증명은 되지 않는 상황이다. 그러나 아직 증명은 되지 않는 상황이다.
NP-hard 문제란 NP 에 속하는 어떤 문제보다도 어렵거나 같은 정도로 어려운 문제를 말한다.
NP 완전 또는 NP-hard 문제에 대해서 현재 알려져 있는 알고리즘의 복잡도는 최악의 경우 입력 크기에 대해 지수 함수가 된다. 그래서 NP-hard 라는 것이 알려져 있는 최적화 문제에 대해서 구하는 답이 반드시 최적해가 아니라고 하더라도 최적해에 가까운 것이면 된다. 그러나 답을 출력할 때까지의 시간은 다항식 가능하다면 O(n) 또는 O(n2) 정도로 하는 것이 바람직하며 실용적으로는 이것으로 충분한 경우가 있다. 이와 같이 최적해에 가까운 답을 근사해라고 하고 그것을 구하는 (결정성) 알고리즘을 근사 알고리즘 (approximation algorithm) 이라고 한다.
근사 알고리즘을 평가하는 척도로는 일반적인 알고리즘과 마찬가지로 시간 복잡도와 영역 복잡도 이외에 그 알고리즘에서 얻어지는 답이 최적해에 어느 정도 가까운가를 평가하는 정밀도 (accuracy) 라는 것이 있다. 물론 정밀도와 복잡도면에서 모두 뛰어난 알고리즘이 있으면 가장 바람직하지만, 그렇지 않은 경우에는 정밀도는 좋지만 효율이 좋지 않은 알고리즘과 효율은 좋으나 정밀도가 나쁜 알고리즘을 문제의 상황에 따라서 잘 나눠서 사용할 필요가 있다.
여기서 다루려고 하는 문제는 순회 세일즈맨 문제에 다음과 같은 제한을 추가한 문제이다 (정점 x 와 y 를 연결하는 변의 무게 (길이) 를 dxy 라고 표현한다.)
(1) 그래프상에 있는 각 변의 길이는 0이상
(2) 그래프상에 있는 임의의 세 정점 A, B, C 에 대해서, dAB + dBC ≥ dAC
첫 번째 조건은 임의의 한 정점에서 다른 정점을 방문했을 때, 도리어 값이 줄어 드는 경우는 없다는 것을 의미한다. 그리고, 두 번째 조건은 정점 A 에서 정점 C 를 방문할 때 정점 B 를 통해서 가는 것보다도 직접 가는 쪽이 좋다는 것을 의미한다. 이 식을 삼각 부동산이라고 한다.
이들 두 조건은 실제의 문제에 적용하는 상황을 생각하면 매우 자연스러운 조건이다. 이들 조건을 추가했을 때의 순회 세일즈맨 문제를 유클리드적 순회 세일즈맨 문제 (Euclidean traveling salesman problem) 라고 한다. 여기서는 그래프의 정점 수는 n 이라고 하고 변의 개수는 n(n - 1)/2 라고 한다. 이 문제의 경우에는 모든 두 정점 사이에는 변이 존재한다는 점을 주의해야 하는데, 변이 없다는 것은 dAB = ∞ 라고 해석할 수 있지만 이것은 두 번째 조건에 어긋난다.
위의 문제를 해결할 수 있는 가장 단순한 알고리즘 (단순 탐욕법) 을 소개하기로 한다.
우선 임의의 한 정점 (u 라고 한다) 을 택하고 정점 u 에 연결되어 있는 변 중에서 무게가 가장 적은 변 ((u, v) 라고 한다) 을 택해서 정점 v 로 이동한다. 이번에는 정점 v 에 연결되어 있는 변 중에서 무게가 가장 적은 것을 택하는데, 이 때 정점 v 에서는 변 (v, u) 를 대상에서 제외한다. 이와 같이 각 정점에서 무게가 가장 적은 변 (이미 지나온 정점으로 향하는 변을 제외) 을 선택하는 조작을 반복해서 마지막에 정점 u 에 되돌아 오게 되면 이것이 하나의 답이 된다.
그러나, 이 방법은 정밀도가 그다지 좋지 않으며, 얻어지는 경로의 길이가 최악의 경우에 최적해의 O(log n) 배나 되는 경우가 있다. 그러나 실제적인 순회 세일즈맨 문제의 경우에는 이와 같은 단순한 방법으로도 충분한 경우가 있다는 것이 알려져 있다.
다음은 이 알고리즘을 평가하기로 한다.
각 정점에서는 그 정점에 인접해 있는 변을 한번씩 조사하는데, 이 때 지금까지 지나온 정점으로 되돌아 가는 것을 제외한 변 중에서 가장 적은 변을 구한다. 각 정점에 인접해 있는 변의 개수는 n - 1 이므로 전체 복잡도는 O(n2) 이 된다.
이외에도 삽입법이라든가 최소목법 등의 방법을 이용하면 정밀도가 높은 답을 구할 수 있는데, 이들 방법에 대해서는 생략하기로 하고, 참고 문헌을 참고로 하기 바란다.
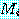 의 크기는
의 크기는 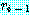 행,
행, 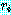 열로 한다.
열로 한다.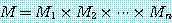
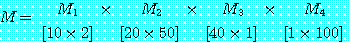
 의 치수를 나타낸다. 일반적인 방법을 이용하면 p × q차 행렬과 q × r 차 행렬의 곱셈은 p × q × r 번의 연산을 필요로 하므로, M 을
의 치수를 나타낸다. 일반적인 방법을 이용하면 p × q차 행렬과 q × r 차 행렬의 곱셈은 p × q × r 번의 연산을 필요로 하므로, M 을 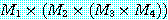 의 순으로 계산하면 125000 번의 연산이 필요하지만
의 순으로 계산하면 125000 번의 연산이 필요하지만 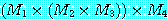 순으로 계산하면 2200 번의 연산이면 된다. 이들 연산수를 살펴보기 위해 다음과 같은 동적 계획법을 이용하면 된다.
순으로 계산하면 2200 번의 연산이면 된다. 이들 연산수를 살펴보기 위해 다음과 같은 동적 계획법을 이용하면 된다.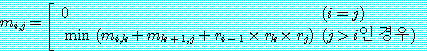
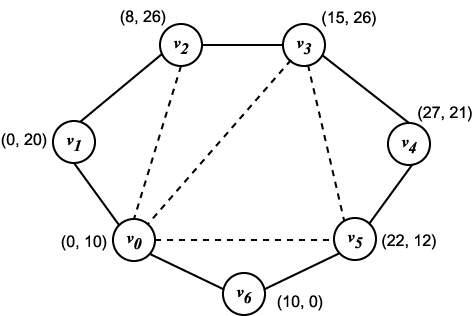

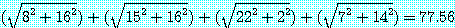 이고, 그림 8 과 같은 분할 코스트는 변 (1, 3), (1, 4), (1, 5), (1, 6) 의 길이의 합계 즉,
이고, 그림 8 과 같은 분할 코스트는 변 (1, 3), (1, 4), (1, 5), (1, 6) 의 길이의 합계 즉, 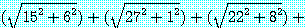
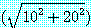 =45.16이다.
=45.16이다.
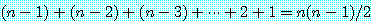
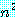 ) 이 된다.
) 이 된다.