<목 차>
 invalid-file
invalid-file- 개 요
- USB 이동매체를 이용한 악성코드 전파기법 소개
- 악성행위
- 이동형 저장장치 자동실행 방지
- 감염 시 조치방법
출처 : 한국정보보호진흥원 인터넷침해사고대응지원센터
<목 차>
- 개 요
- USB 이동매체를 이용한 악성코드 전파기법 소개
- 악성행위
- 이동형 저장장치 자동실행 방지
- 감염 시 조치방법
출처 : 한국정보보호진흥원 인터넷침해사고대응지원센터
2006년은 컴퓨터 바이러스가 제작 된지 20주년을 기념하는 한 해였다.
이 20년이라는 긴 세월 속에서 컴퓨터 바이러스는 파일 감염을 목적으로 하는 바이러스(Virus)로부터 네트워크를 통한 급속한 확산을 시도하는 웜(Worm) 그리고 데이터 유출을 위한 트로이목마(Trojan Horse)에 이르기까지 다양한 모습으로 발전하였다.
이러한 악성 코드의 위협은 해가 갈수록 증가 추세를 이루고 있으며 기술적인 면에서도 더욱더 위험성을 더해 가고 있어 컴퓨터 사용자들을 불안하게 만들고 있는 것이 사실이다.
그러나 이렇게 증가하는 악성 코드의 위협 에 맞서는 안티 바이러스(Anti-Virus) 업체 역시 새로운 악성 코드의 위협들로부터 컴퓨터 시스템을 보호하기 위해 다양한 대응 방안들을 활발하게 연구하고 있다.
이러한 다양한 대응 방안들의 기본 전제가 바로 “급속하게 확산되는 알려지지 않은 새로운 악성 코드에 어떻게 대응할 것인가?”라는 점이다. 이 명제는 결국 새로운 악성 코드를 어떻게 효과적으로 탐지할 것인가의 문제로 볼 수 있다.
이러한 문제를 해결하기 위해 안티 바이러스(Anti-Virus) 업체의 알려지지 않은 악성 코드 위협에 대응하기 위한 다양한 안티 바이러스(Anti-Virus) 탐지 기법들과 그 탐지 기법들의 특징들에 대해서 알아 보도록 하자.
1. 악성 코드의 증가와 조기 대응의 필요성
본 글의 서두에서 악성 코드는 해가 갈수록 증가하고 있다고 이야기 하였다. 이러한 사실은 아래 [그림 1]의 안철수연구소 시큐리티대응센터(ASEC, AhnLab Security Emergency response Center)에서 발행하는 ASEC Annual Report 2005 자료를 참고하면 더욱 명확하게 이해가 될 것이다.
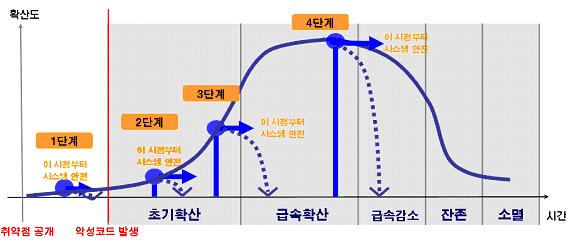
1988년부터 2005년도까지 년도 별 악성 코드 피해신고 건수를 나타낸 [그림 1]에서와 같이 악성 코드의 수치적인 증가는 단순하게 악성 코드 형태의 다양화를 넘어서 악성 코드에 대한 안티 바이러스(Anti-Virus) 업체의 신속한 대응 자체가 어려울 정도로 심각한 문제를 유발하고 있다. 신속한 대응이 어려워지게 된다는 것은 결국 악성 코드로부터 피해를 입는 컴퓨터 시스템의 수치가 증가하는 문제로 볼 수 있다.
[그림 2]가 바로 신속한 대응과 컴퓨터 시스템의 피해와 상관관계를 나타낸 그래프이다. 이 그래프에서와 같이 어느 단계에서 대응이 가능해지냐에 따라서 악성 코드의 피해가 판이하게 달라지게 되는 것을 알 수 있다.
일반적으로 악성 코드 대응에서 가장 이상적인 형태의 대응을 말하는 [1 단계]에서는 운영체제에서 발견된 취약점을 사전에 분석 한 후 조치를 취하여 실제 해당 취약점을 공격하는 악성 코드가 발견되더라도 해당 악성 코드에 의한 피해가 발생하지 않도록 조치를 취하는 단계이다
그러나 실제로는 악성 코드가 특정 운영체제나 프로그램의 어떠한 취약점을 사용할 지 판단할 수 없으며 모든 악성 코드가 특정 운영체제나 프로그램의 취약점을 이용하지는 않는다. 그리고 설령 그 판단을 할 수 있다 하더라도 해당 취약점들을 공격하는 악성 코드의 실제 제작 여부에 대해서는 전혀 예측을 할 수 없게 된다.
그러므로 실제 안티 바이러스(Anti-Virus) 업체에게 가장 많은 고민과 해결책을 요구 하는 부분이 바로 [2 단계]이다. [2 단계]에서는 특정 악성 코드의 확산 초기에 최단 시간에 이를 탐지하여 빠르게 스캐닝 엔진(Scanning Engine)에 반영하여 악성 코드가 확산되더라도 최신 엔진의 안티 바이러스(Anti-Virus) 소프트웨어가 설치된 컴퓨터 시스템에서는 더 이상의 피해가 발생하지 않도록 피해와 확산 억제성의 대응이 가능해지는 단계이다.
그러나 [3 단계]와 [4 단계]와 같이 초기 확산 시에 신속하게 대응을 진행하지 못하게 된다면 그 피해는 걷잡을 수 없을 정도로 커지게 된다. 그러므로 악성 코드 초기 확산 시에 신속한 대응이 진행되어야만 피해를 최소화할 수가 있게 된다.
그러나 아무리 빠르게 악성 코드 샘플을 확보하고 스캐닝 엔진(Scanning Engine)을 제작하여 배포한다고 하더라도 스캐닝 엔진(Scanning Engine)이 제작되는 그 1분, 1초의 시간 사이에서도 악성 코드에 감염되어 피해를 입는 컴퓨터 시스템이 발생하기 마련이다.
그러므로 안티 바이러스(Anti-Virus) 업체에서는 알려지지 않은 새로운 악성 코드를 탐지할 수 있는 다양한 탐지 기법들을 연구하여 조금 더 효율적이고 효과적인 신속한 대응이 가능하도록 하고 있다.
2. 파일기반의 탐지 기법(File Base Detection Tech)
현재까지 알려진 안티 바이러스(Anti-Virus) 소프트웨어 대부분이 파일 기반(File Base)의 진단법을 사용하고 있다. 이는 대부분의 악성 코드가 특정 운영체제에서 실행되기 위해서는 해당 운영체제에서 실행이 가능한 특정한 파일 형태로 되어 있다는 점에서 기인한 것이다.
그러므로 악성 코드가 윈도우 시스템(Windows System)에서 실행되기 위해서는 윈도우 시스템에서 실행 가능한 파일 포맷인 PE(Portable Executable) 형식을 가지고 있어야 된다는 것이다.
이러한 PE(Portable Executable) 형식의 악성 코드를 진단하기 위해서는 안티 바이러스(Anti-Virus) 소프트웨어 역시 이러한 파일 형식을 인식하고 악성 코드로 판단을 내릴 수 있는 특정 형식의 시그니처(Signature)를 가지고 있어야 된다.
이러한 진단법이 대부분의 안티 바이러스(Anti-Virus) 소프트웨어가 사용하는 시그니처 기반(Signature Base) 또는 스트링(String – 여기서 말하는 스트링이란 일반적인 문자열이 아닌 파일의 헥사코드(Hex Code)를 의미하는 것이다.) 검사 방식이라고 이야기하는 진단법이다.
이러한 시그니처 기반(Signature Base)의 진단법은 악성 코드로 분류된 파일의 특정 부분 또는 고유한 부분을 검사의 대상으로 삼으므로 오탐(False Positive)과 미탐(False Negative)을 최소화하는 정확한 진단이 가능하다는 것과 파일 검사 시에 파일들의 특징적인 부분들만 비교 함으로 빠른 스캐닝(Scanning)을 장점으로 들 수 있다.
그러나 이러한 시그니처 기반(Signature Base) 진단법은 악성 코드의 파일 자체가 몇 백 바이트(Byte)만 바뀌어도 진단이 되지 않는 미탐(False Negative)이 발생함으로 파일이 조금만 변경된 새로운 변형에 대해서는 대응을 할 수가 없게 된다. 그리고 기존에 알려진 악성 코드에 대해서만 대응을 할 수 있으므로 새로운 형태의 알려지지 않은 악성 코드에 대해서는 대응을 할 수 없다는 단점을 가지고 있다.
1) 휴리스틱 탐지 기법 (Heuristic Detection Tech)
이러한 시그니처 기반(Signature Base)의 진단법이 가지고 있는 한계를 극복하고자 개발한 탐지 기법 중 하나가 휴리스틱 탐지(Heuristic Detection) 기법이다.
휴리스틱 탐지(Heuristic Detection) 기법은 일반적인 악성 코드가 가지고 있는 특정 폴더에 파일 쓰기와 특정 레지스트리 부분에 키 생성과 같은 명령어(Instruction)들을 스캐닝 엔진(Scanning Engine)에서 시그니처(Signature)화하여 파일을 검사할 때 이를 사용한다.
그래서 검사 대상 파일이 휴리스틱 시그니처(Heuristic Signature - 이 것을 부스터(Booster)라고도 한다.)와 비교를 통하여 일반적으로 알려진 악성 코드와 얼마나 높은 유사도를 가지고 있는지를 판단하여 알려지지 않은 새로운 악성 코드를 탐지하는 기법이다.
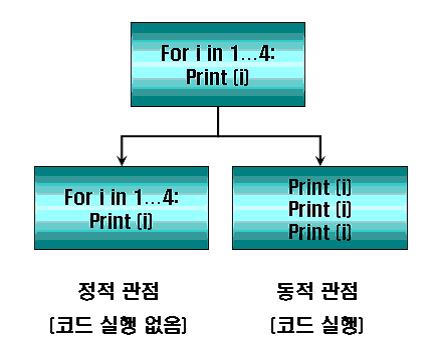
이러한 휴리스틱 탐지(Heuristic Detection) 기법은 검사 대상이 되는 파일에 대해서 휴리스틱(Heuristic) 검사 시에 스캐닝 엔진(Scanning Engine)이 어떠한 형태를 취하는가 에 따라서 아래와 같이 크게 2가지 형태로 나누어서 볼 수 있다.
- 동적 휴리스틱 탐지 기법 (Dynamic Heuristic Detection Tech)
동적 휴리스틱 탐지(Dynamic Heuristic Detection) 기법은 검사 대상이 되는 파일을 가상화된 영역 또는 운영체제와 분리된 특정 공간에서 파일 실행(File Execution)을 통해 수집한 다양한 정보들을 휴리스틱 시그니처(Heuristic Signature)와 비교를 통하여 검사를 수행하는 기법이다.
즉 검사 대상이 되는 파일이 어떠한 형식으로든 실행이 되어야 하며 이러한 점으로 인해 런 타임 휴리스틱 탐지 (Run-Time Heuristic Detection) 기법이라고도 불리고 있다. 이러한 동적 휴리스틱 탐지(Dynamic Heuristic Detection) 기법은 이 후에 다룰 에뮬레이터(Emulator)과 샌드박스(Sandbox)에서 조금 더 자세하게 알아 보도록 하자.
- 정적 휴리스틱 탐지 기법 (Static Heuristic Detection Tech)
정적 휴리스틱 탐지(Static Heuristic Detection) 기법은 동적 휴리스틱 탐지(Dynamic Heuristic Detection) 기법과는 반대로 파일에 대해서 어떠한 형식의 파일 실행(File Execution) 없이 파일 자체를 그대로 스캐닝 엔진(Scanning Engine)에서 읽어 들여 휴리스틱 시그니처(Heuristic Signature)와 비교를 수행하는 탐지 기법이다.
[그림 4] 정적 휴리스틱(Static Heuristic)과 동적 휴리스틱(Dynamic Heuristic)
이 외에도 네거티브 휴리스틱(Negative Heuristic – 이 것을 스토퍼(Stopper)라고도 한다.)탐지 기법도 있다. 이는 이제까지 기술한 휴리스틱 탐지(Heuristic Detection) 기법과는 반대로 악성 코드에서 전형 사용하지 않은 윈도우 팝업 창 생성과 같은 명령어(Instruction)들이 존재 할 경우에는 악성 코드로 판단하지 않는 기법이다.
즉, 휴리스틱 시그니처(Heuristic Signature)와 동일한 명령어들이 존재하지 않는 부정의 경우에만 악성 코드로 판단한다.
이러한 형태들의 휴리스틱 탐지(Heuristic Detection) 기법은 기존에 알려진 악성 코드도 탐지가 가능하며 알려지지 않은 새로운 악성 코드 역시 탐지가 가능하다는 점에서 매력적인 탐지기법이라고 할 수 있다.
그러나 이 탐지 기법은 정상 파일을 악성 코드라고 판단하게 되는 오탐(False Positive)의 발생이 가장 큰 단점으로 작용한다. 특히나 파일을 삭제하고 치료하는 안티 바이러스(Anti-Virus) 소프트웨어의 특성상 오탐(False Positive)율이 높게 된다면 컴퓨터 시스템 자체에 큰 문제를 유발할 수 있게 됨으로 이는 치명적인 문제점이라고 볼 수 있다.
2) 제너릭 탐지 기법 (Generic Detection Tech)
앞서 설명한 휴리스틱 탐지(Heuristic Detection) 기법 외에도 알려지지 않은 악성 코드를 탐지하기 위한 기법 중에는 제너릭 탐지(Generic Detection) 기법이라는 것이 있다.
이 탐지 기법은 유사한 형태의 악성 코드 집합을 탐지하기 위해 해당 집합을 이루는 악성 코드 파일들의 공통된 코드 영역(Code Section)을 진단하도록 한다.
그러므로 소스 코드(Source Code)상에서 사용자 코드(User Code)의 변화가 없거나 약간의 수정만 가하여 컴파일(Compile)만 새롭게 하여 생성한 새로운 악성 코드 변형들에 대해 탐지가 가능함으로 유사한 형태의 악성 코드 변형들이 지속적으로 제작되더라도 시그니처(Signature) 업데이트 없이 탐지가 가능하다는 장점이 있다.
이러한 제너릭 탐지(Generic Detection) 기법에서는 일반적으로 파일에 대한 OPcode(Operation Code) 명령어 비교 방식이 많이 사용되고 있다.
이 OPcode(Operation Code) 명령어 비교 방식에는 크게 와일드카드 비교(Wildcard Matching – Don’t Care 비교라고도 한다)와 미스매칭(Mismatching) 방식으로 나누어진다.
먼저 와일드카드 비교(Wildcard Matching)는 유사한 형태의 악성 코드 변형들의 특정 코드 영역(Code Section)에서 사용되는 OPcode(Operation Code) 명령들이 조금씩만 다르고 동일할 경우 해당 다른 OPcode(Operation Code) 명령어 부분에 와일드카드를 적용하여 다른 OPcode(Operation Code) 명령어가 사용되어도 이를 무시하겠다는 것이다.
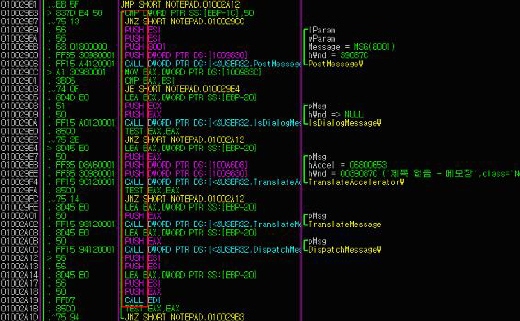
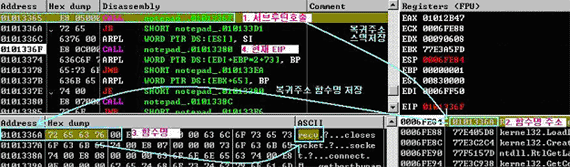
[그림 5] 메모장(Notepad.exe) 프로그램의 OPcode(Operation Code) 명령어들
[그림 5]를 예로 들어 메모장 프로그램을 원본 악성 코드라고 가정을 한다면 이 원본 악성 코드의 일부 OPcode(Operation Code) 명령어들은 [그림 5]의 붉은색 박스 영역의 순서대로 진행된다.
이렇게 PUSH, PUSH, PUSH, PUSH 순서로 진행되는 OPcode(Operation Code) 명령어들이 다른 악성 코드 변형들에서는 PUSH, PUSH, PUSH, MOV가 사용된다면 마지막 MOV 부분을 와일드카드(Wildcard)로 적용하여 마지막 4번째 OPcode(Operation Code) 명령은 어떠한 것이 사용되더라도 이에 구애 받지 않겠다는 것이다.
이렇게 적용하게 되면 원본 악성 코드와 변형 악성 코드의 전체 OPcode(Operation Code) 명령어 진행 순서는 유사한데 일부가 조금 틀리더라도 모두 진단하게 되는 효과를 구현할 수가 있다.
그러나 미스매칭(Mismatching) 방식은 와일드카드 비교(Wildcard Matching)와는 반대로 MMX(Multi Media eXtension) 명령어 또는 FPU(Floating Point Unit) 명령어와 같이 악성 코드에서 잘 사용되지 않는 명령어들이 [그림 5]의 해당 붉은색 박스영역과 같이 특정 부분에 사용 될 경우, 해당 파일을 악성 코드 변형으로 판단하지 않겠다는 것이다. 이런 미스매칭(Mismatching) 방식은 앞서 설명한 네거티브 휴리스틱(Negative Heuristic) 탐지 기법과 기본적인 개념은 동일하다고 볼 수 있다.
그러나 이러한 제너릭 탐지(Generic Detection) 기법은 악성 코드의 공통된 코드 영역을 진단함으로 새로운 악성 코드 변형들이 제작되더라도 탐지가 가능하다는 장점이 있지만 새로운 악성 코드 변형들이 완전히 새로운 OPcode(Operation Code) 명령어 순서로 진행된다던가 아니면 안티 디버깅(Anti-Debugging)과 암호화(Encryption) 등과 같이 실행 파일 보호 기법을 통해 OPcode(Operation Code) 명령어의 진행 순서를 뒤섞어 놓게 된다면 스캐닝 엔진(Scanning Engine)에서는 이를 탐지하지 못하게 되는 문제가 발생할 수가 있다.
이상으로 파일을 기반으로 알려지지 않은 악성 코드 탐지 기법들에 대해서 알아 보았다. 다음으로는 파일 실행을 통해서 탐지하는 동적 휴리스틱 탐지(Dynamic Heuristic Detection) 기법 설명 시에 잠시 언급한 에뮬레이터(Emulator)와 샌드박스(Sandbox)에 대해서 알아보도록 하자.
3. 에뮬레이터(Emulator)과 샌드박스(Sandbox)
앞 장에서 설명한 새로운 악성 코드 탐지기법들은 모두 실행 파일(Executable File) 자체를 대상으로 한 탐지 기법들이다.
그러나 이번 장에서 설명하는 에뮬레이터(Emulator)와 샌드박스(Sandbox)는 모두 실행 파일(Executable File) 자체에 관한 탐지 기법이 아니라 해당 실행 파일(Executable File)의 실행을 통해 수집한 정보들을 이용하여 새로운 악성 코드를 탐지하는 기법들이다.
그러므로 앞서 이야기한 바와 같이 실행 파일(Executable File)의 실행을 통하여 새로운 악성 코드를 탐지하는 동적 휴리스틱 탐지(Dynamic Heuristic Detection) 기법과도 상당히 밀접한 연관 관계를 가지고 있는 것이다.
1) 에뮬레이터(Emulator)
사전적인 의미에서 에뮬레이터(Emulator)는 대리 실행기 라는 의미를 가지고 있다. 대리 실행기 라는 의미에서와 같이 에뮬레이터(Emulator)는 실제 컴퓨터 시스템 상에서 실행 파일(Executable File)을 직접적으로 실행하는 것이 아니라 실제 컴퓨터 시스템에 가상(Virtual)의 환경이나 가상의 하드웨어(Hardware) 이미지를 생성하여 해당 가상 하드웨어(Hardware)를 통하여 간접적으로 실행하는 것을 의미한다.
이러한 의미로 인해 일부에서는 에뮬레이터(Emulator)를 이용한 탐지 기법을 코드 에뮬레이션(Code Emulation) 또는 CPU 에뮬레이션(CPU Emulation) 이라고도 이야기 한다.
이 탐지 기법은 실제 컴퓨터 상에서 스캐닝 엔진(Scanning Engine)이 검사를 수행하지만 컴퓨터 시스템 내부에 가상의 CPU와 메모리 등의 가상의 환경을 제공하여 실행 파일(Executable File)을 실행하고 정보를 수집함으로 실제 컴퓨터 시스템에서는 악성 코드로 인한 어떠한 감염 피해도 발생하지 않는다. 이러한 점으로 인해 알려지지 않은 악성 코드를 탐지하기 위한 부분에서는 상당히 강력한 방법이라고 할 수 있다.
이러한 가상의 환경을 이용하는 에뮬레이터(Emulator)가 컴퓨터 시스템에서 구현되기 위해서는 크게 다음과 같은 4가지가 포함 되어야 한다.
- 가상 CPU 환경
실행 파일을 실제 CPU를 이용한 연산과 동일하게 처리하기 위해 일반적인 모든 명령어들뿐만이 아니라 MMX(Multi Media eXtension) 명령어와 FPU(Floating Point Unit) 명령어까지도 모두 처리 할 수가 있어야 한다.
- 가상 메모리 환경
32비트(Bit) 주소 체계에서는 최고 4 기가바이트(GB)까지 확장이 가능하지만 가상의 메모리 환경에서는 이렇게 많은 메모리는 필요하지 않다. 다만, 실행 파일(Executable File)이 실행되었을 때 변경하는 메모리 주소들에 대해 모두 기록하고 이를 추적할 수 있어야 하며 논리적인 메모리 주소와 물리적인 메모리 주소들을 모두 제공할 수 있어야 한다.
- 가상 저장 장치 환경
물리적인 저장 장치와 동일하게 실행 파일(Executable File) 실행 시 발생하는 저장 장치에 대한 파일 읽기 및 쓰기처럼 저장 장치에 대한 I/O(Input/Output)가 발생할 때 에뮬레이터(Emulator)에서는 실제 하드웨어와 동일한 환경을 제공 할 수 있어야 한다.
- 에뮬레이션 제어기(Emulation Controller)
에뮬레이션 제어기(Emulation Controller)는 에뮬레이터(Emulator)에서 가장 핵심이 되는 부분이다. 실행 파일(Executable File)이 가상 환경에서 실행 시 악성 코드로 판단 할 수 있을 정도의 충분한 정보를 수집하고 이를 제어하는 것이 바로 에뮬레이션 제어기(Emulation Controller)이기 대문이다.
그래서 에뮬레이션 제어기(Emulation Controller)에서는 실행 중인 악성 코드를 어느 시점에서 실행을 중단할 것인가와 얼마 정도의 시간을 실행에 소비할 것인가를 판단하고 제어할 수 있어야 한다. 일반적으로는 인텔 X86 CPU에서 에뮬레이션(Emulation)을 수행 하기 위해서는 최소 1,000개에서 최대 30,000개의 CPU 명령어 수행과 함께 45초 정도의 시간 소요를 기본으로 설정 한다.
이렇게 가상의 환경에서 실행 파일(Executable File)을 실행하고 수집된 실행 결과들을 통해서 악성 코드로 판단하는 에뮬레이터(Emulator)는 실제 시스템에 전혀 감염의 피해를 입히지 않고 알려지지 않은 악성 코드를 탐지할 수 있다는 점에서는 상당히 강력한 방법이라고 이야기 하였다.
하지만 에뮬레이터(Emulator)는 스캐닝 엔진(Scanning Engine)이 실행 파일(Executable File)을 검사 할 때마다 모두 가상의 환경에서 실행을 하고 분석을 해야 된다는 점에서는 컴퓨터 시스템에 대한 자원 소모가 커지게 되는 부담을 안고 있다. 이 문제로 인해 전반적인 스캐닝 엔진(Scanning Engine)의 검사 속도 저하로 이어지는 점이 가장 큰 단점이라고 할 수 있다.
2) 샌드박스(Sandbox)
에뮬레이터(Emulator)와 샌드박스(Sandbox)는 실행 파일(Executable File)의 실행을 통하여 수집된 정보를 통하여 악성이라고 판단하는 점에서는 유사한 형태라고 할 수 있다. 그러나 에뮬레이터(Emulator)와 샌드박스(Sandbox)의 가장 큰 차이점은 어떠한 형태로 실행 파일(Executable File)을 실행하고 어떠한 방식으로 악성 코드로 판단할 수 있는 정보들을 수집하는가에 가장 큰 차이점을 가지고 있다.
일반적으로 샌드박스(Sandbox)는 어플리케이션 에뮬레이터(Application Emulator)라고도 알려져 있는데 이러한 명칭에서 알 수 있듯이 샌드박스(Sandbox)는 에뮬레이터(Emulator)와는 달리 가상의 공간을 생성하는 것이 아니라 실제 컴퓨터 시스템상에서 바로 실행 파일(Executable File)을 실행하고는 정보를 수집한다는 점에서 가장 큰 차이점을 가지고 있다.
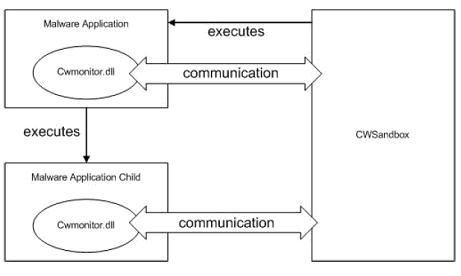
일반적인 어플리케이션 에뮬레이터(Application Emulator)로 널리 알려져 있는 CWSandbox는 [그림 6]과 같은 기본적인 구조로 되어 있다. CWSandbox의 경우 실행 파일(Executable File)이 실행되면 해당 파일의 스레드(Thread)로 모니터링 모듈인 CWMonitor.dll 파일을 인젝션(Injection) 시킨다. 인젝션(Injection) 이 후 해당 실행 파일(Executable File)이 실행되는 되는 모든 절차를 추적하여 해당 정보를 모두 CWSnadbox로 전달하게 된다.
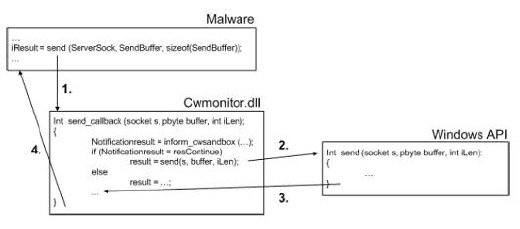
그리고 실행 파일(Executable File)이 실행되는 과정에서 발생하는 윈도우 API(Windows API) 호출 모두를 API 후킹(API Hooking) 기법을 이용하여 가로챈 후 CWSandbox로 전달된다.
전달된 윈도우 API(Windows API) 호출은 CWSandbox를 통해 윈도우 커널 레벨(Windows Kernel Level)로 전달하는 정상적인 절차를 수행하게 되고 호출되는 윈도우 API(Windows API) 역시 호출한 해당 실행 파일(Executable File)로 바로 전달하는 것이 아니라 CWSandbox를 거쳐서 전달하게 되는 것이다. 이러한 과정을 표현한 것이 바로 [그림 7]과 같다.
그런데 여기에서 바로 어플리케이션 에뮬레이터(Application Emulator)인 샌드박스(Sandbox)의 가장 큰 특징이 나타난다. 호출 되는 윈도우 API(Windows API)가 CWSandbox를 통해 실행 파일(Executable File)로 전달 된 후 다시 그 리턴 값이 윈도우 운영체제로 바로 전달 되는 것이 아니라 CWSandbox를 통해 전혀 다른 리턴 값을 윈도우 운영체제로 전달하게 된다는 것이다.
이러한 다른 리턴 값을 전달하게 됨으로 실행 파일(Executable File)이 악성 코드여서 감염으로 인해 발생하는 악의적인 기능들이 모두 CWSandbox에 의해 걸러지게 됨으로 실질적인 컴퓨터 시스템에는 감염으로 인한 피해가 발생하지 않게 된다. 그리고 수집된 윈도우 API(Windows API) 호출과 리턴된 값과 같은 정보들을 통하여 CWSandbox는 해당 실행 파일(Executable File)이 알려지지 않은 악성 코드인지 판단을 하게 된다.
그러나 에뮬레이터(Emulator)와 같이 가상의 공간이 아닌 실제 컴퓨터 시스템의 환경에서 실행 파일(Executable File)을 실행하는 샌드박스(Sandbox) 역시 윈도우 응용 프로그램이다. 그러므로 샌드박스(Sandbox)가 특정 악성 코드를 정상적으로 제어하지 못하게 될 경우에는 그 감염으로 인한 피해가 고스란히 실제 시스템으로 전달되게 됨으로 예측하지 못하는 문제가 발생할 가능성이 크다.
이제까지는 실행 파일(Executable File)의 실행을 통해서 알려지지 않은 악성 코드를 탐지 할 수 있는 에뮬레이터(Emulator)와 샌드박스(Sandbox)에 대해서 알아 보았다. 하지만 다음 장에서는 일반적인 윈도우 실행 파일 포맷이 아닌 전자 메일로 형태는 급속한 확산을 시도하는 알려지지 않은 매스 메일러 웜(Mass Mailer Worm)을 탐지 할 수 있는 기법에 대해서 알아 보도록 하자.
4. MIME 필터링 탐지 기법 (MIME Filtering Detection Tech)
필자가 악성 코드를 분석하고 대응을 하면서 기억에 남는 악성 코드들을 이야기하라고 한다면 그 중에 하나가 바로 베이글 웜(Win32/Bagle.worm), 넷스카이 웜(Win32/Netsky.worm) 그리고 마이둠 웜(Win32/Mydoom.worm)과 같이 전자메일에 자신의 복사본을 첨부하여 대량으로 발송하는 매스 메일러 웜(Mass Mailer Worm)이다.
이러한 매스 메일러 웜(Mass Mailer Worm)은 감염된 시스템에서 메일 주소를 수집하여 대량으로 전자메일을 발신함으로 만약 유럽에서 확산되었다면 지구 반대편인 한국까지 웜(Worm)이 첨부된 전자메일이 전달되는데 에는 서너 시간이면 충분할 정도로 급속하게 확산된다. 특히나 대량의 전자메일이 전송됨으로 기업의 전산 환경에서는 전자메일을 수신하는 메일 서버에도 엄청난 부하가 가중됨으로 정상적인 일반 메일의 전송이 느려지게 되거나 어려워 질 수도 있게 된다.
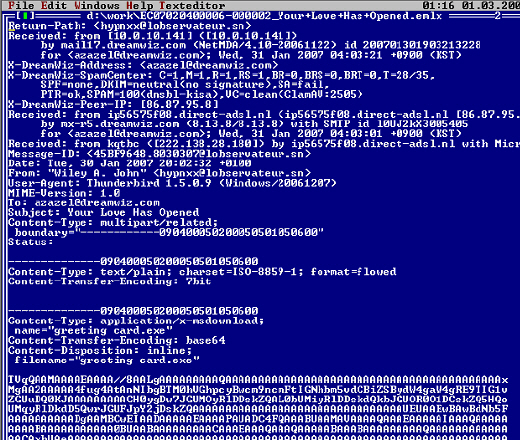
이러한 매스 메일러 웜(Mass Mailer Worm) 역시 일반적인 전자메일과 동일하게 베이스64(Base64)로 인코딩(Encoding)된 MIME(Multi-Purpose Internet Mail Extensions) 형태로 전송된다.
위 [그림 8]과 같은 형태로 되어 있는 매스 메일러 웜(Mass Mailer Worm)을 탐지하기 위해서 가장 쉽게 적용할 수 있는 부분이 바로 콘텐츠 필터링(Contents Filtering) 방식이다.
콘텐츠 필터링(Contents Filtering) 방식이란 급속하게 확산되는 매스 메일러 웜(Mass Mailer Worm)이 발견되었을 때 해당 매스 메일러 웜(Mass Mailer Worm)이 전송하는 전자메일 형태, 즉 메일 제목(Subject), 메일 본문(Body) 그리고 첨부파일(Attachment File) 명칭과 같이 특징적인 문구로 탐지하는 것이다.
앞서 설명한 파일 기반 탐지(File Base Detection) 기법으로 설명하자면 시그니처 기반(Signature Base)의 진단법과 유사한 개념으로 이해하면 될 것이다. 이 콘텐츠 필터링(Contents Filtering) 기법이 가능한 것이 매스 메일러 웜(Mass Mailer Worm) 역시 윈도우 시스템에서 실행되는 응용 프로그램의 형태임으로 자신의 복사본을 전송할 때 프로그래밍화된 고정된 형태의 전자메일 형태로 전송하기 때문이다.
그러나 이 방식은 이미 매스 메일러 웜(Mass Mailer Worm)이 확산되고 있다는 것을 알고 그 악성 코드가 어떠한 형태의 전자메일을 발송한다는 것 역시 이미 알고 있어야 됨으로 전혀 알려지지 않은 새로운 악성 코드를 탐지할 수는 없다.
다만 스캐닝 엔진(Scanning Engine)이 업데이트 되기 전인 초기 확산 단계에 적용하여 메일 서버의 부하와 매스 메일러 웜(Mass Mailer Worm)의 기업 전산망으로 유입되는 것을 조기에 효과적으로 차단할 수가 있다.
1) 첨부 파일 탐지 기법 (Attachment File Detection Tech)
전자메일을 이용하여 급속하게 확산되는 알려지지 않은 매스 메일러 웜(Mass Mailer Worm)을 탐지할 수 있는 기법 중 하나가 전자메일에 첨부된 첨부 파일 탐지(Attachment File Detection) 기법이다.
앞서 설명한 바와 같이 매스 메일러 웜(Mass Mailer Worm)이 전송하는 전자메일 역시 베이스64(Base64)로 인코딩(Encoding)된 MIME(Multi-Purpose Internet Mail Extensions) 형태로 전송된다고 하였다.
특히 매스 메일러 웜(Mass Mailer Worm)은 자신의 복사본을 첨부 파일로 사용하는데 일반적인 실행 파일(Executable File)이 전자메일에 첨부되기 위해서는 파일 형태 역시 베이스64(Base64)로 인코딩(Encoding)되어야 한다.
최근에 발견되는 대부분의 악성 코드는 UPX, FSG 등과 같은 실행 압축(Packer)이라는 실행 파일 보호 기법을 이용하여 악성 코드 제작자가 안티 바이러스(Anti-Virus) 연구원들의 분석을 지연시키고자 하고 있다.
그런데 이러한 실행 압축(Packer)이라는 실행 파일 보호 기법이 적용된 실행 파일(Executable File)이 베이스64(Base64)로 인코딩(Encoding) 되면 재미있는 현상이 나타나게 된다. 여기서 베이스64(Base64)로 인코딩(Encoding) 된다는 것은 4개의 7 비트(Bit) 아스키(ASCII) 문자로 표현되도록 원래의 파일에서 각 3 바이트(Byte)씩을 4개의 6 비트(Bit) 단위로 나누어주게 되는 것이다.
이렇게 실행 압축(Packer)된 실행 파일(Executable File)이 베이스64(Base64)로 인코딩(Encoding)되면 실행 압축(Packer)별로 유사한 코드 형태를 가지게 된다는 것이다. 이렇게 인코딩(Encoding)된 실행 압축(Packer) 파일의 유사한 코드 부분을 휴리스틱 시그니처(Heuristic Signature)로 적용하게 되면 알려지지 않은 매스 메일러 웜(Mass Mailer Worm)이 특정 실행 압축(Packer)으로 되어 있을 경우에는 모두 탐지가 가능해지게 된다.
이상으로 급속하게 확산되는 알려지지 않은 매스 메일러 웜(Mass Mailer Worm)을 첨부 파일을 이용하여 탐지하는 기법에 대해서 알아 보았다. 다음 장에서는 이제까지 설명하였던 알려지지 않은 악성 코드 탐지 기법들과는 조금 다른 접근법을 가진 실제 컴퓨터 시스템에서 실행 파일이 실행되어 나타나는 다양한 행위를 바탕으로 알려지지 않은 악성 코드를 탐지하는 행위 기반 탐지 기법(Behavior Detection)에 대해서 알아 보도록 하자.
5. 행위 기반 탐지 기법 (Behavior Detection Tech)
최근 들어 안티 바이러스(Anti-Virus) 업계뿐만이 아니라 일반적인 보안 업체에서도 많은 주목을 받고 있는 탐지 기법 중 하나가 바로 이 행위 기반 탐지 기법(Behavior Detection)이다.
이 행위 기반 탐지 기법(Behavior Detection)은 실행 파일(Executable File)의 실행을 통해서 알려지지 않은 악성 코드를 탐지한다는 면에서는 에뮬레이터(Emulator) 또는 샌드박스(Sandbox)와 동일하지 않은가라는 의구심이 들 수가 있다.
그러나 엄밀하게 말해서 에뮬레이터(Emulator)는 실제 컴퓨터 시스템 내에서 가상의 공간을 구성하는 점과 샌드박스(Sandbox)는 실제 컴퓨터 시스템과 실행 파일(Executable File)의 중간에서 이를 가로챈다는 특징으로 인해 행위 기반 탐지 기법(Behavior Detection)과는 다르다고 할 수 있다.
행위 기반 탐지 기법(Behavior Detection)은 일반적으로 크게 하나의 컴퓨터 시스템 내에서 발생하는 행위들에 바탕을 두고 있는 시스템 기반 탐지(System Base Detection) 기법과 전체 네트워크(Network) 내에서 발생하는 행위들에 바탕을 두고 있는 네트워크 기반 탐지(Network Base Detection) 기법 이렇게 2가지로 나누어진다.
그러나 필자의 전문 분야가 실행 파일(Executable File)을 기반으로 한 악성 코드 분석임으로 여기에서는 네트워크 기반 탐지(Network Base Detection) 기법에 대해서는 다루지 않도록 하겠다.
1) 시스템 기반 탐지 기법 (System Base Detection Tech)
시스템 기반 탐지(System Base Detection) 기법은 앞서 설명한 바와 같이 하나의 컴퓨터 시스템 내에서 발생하는 다양한 행위들의 탐지를 바탕으로 하고 있다.
이 탐지 기법 역시 크게 무결성 검사(Integrity Check) 기법과 행위 차단 (Behavior Block) 기법으로 나누어지는데 이 두 기법 모두 실행 파일(Executable File)이 하나의 컴퓨터 시스템에서 실행되는 행위에 대해서 탐지를 한다는 공통점은 있으나 실행이 이루어지고 난 이후에 어떠한 방식으로 알려지지 않은 악성 코드를 탐지하는가에 따라서 구분되고 있다.
- 무결성 검사 기법(Integrity Check)
무결성(Integrity)은 일반적인 정보 보호(Information Security)에서 이야기하는 보안의 3대 구성 요소 중 하나이다. 여기에서 말하는 무결성(Integrity)은 원본 데이터 또는 자료의 왜곡이 없이 순수한 상태를 그대로 유지하는 것을 의미한다.
이러한 의미를 가지고 있는 무결성(Integrity)은 무결성 검사(Integrity Check) 기법에서도 역시 컴퓨터 시스템이 데이터, 실행 파일(Executable File)들과 시스템 자체에 대한 어떠한 변화가 없이 유지되는 상태를 의미하는 것이다.
즉, 무결성 검사(Integrity Check) 기법은 이러한 컴퓨터 시스템의 무결성(Integrity) 상태가 지속적으로 유지되고 있는가를 주기적으로 검사를 수행 하는 것을 이야기 한다.
예를 들어 어떤 컴퓨터에서 30분전에 마지막으로 무결성 검사(Integrity Check)를 수행하여 무결성(Integrity)이 유지되는 것을 확인하였으나 지금 다시 검사를 수행하니 30분전에 존재하지 않았던 특정 실행 파일(Executable File)이 윈도우 시스템 폴더에 생성된 것을 확인하였다면 해당 실행 파일(Executable File)을 악성 코드로 의심해 볼 수가 있다는 것이다.
무결성 검사(Integrity Check)가 수행되는 방식은 최초 악성 코드에 감염되지 않은 깨끗한 컴퓨터 시스템상에 존재하는 주요 실행 파일과 폴더에 대해서 MD5(Message Digest 5)와 같은 해쉬값(Hash)을 계산하여 모두 기록을 하게 된다.
그 이후 앞서 이야기한 바와 같이 특정 시간 단위로 해당 컴퓨터 시스템에서 MD5(Message Digest 5)가 기록된 실행 파일(Executable File)과 폴더에 변경된 또는 존재하지 않던 해쉬값(Hash)이 있는지를 비교하는 작업을 수행하게 되는 것이다.
이러한 무결성 검사(Integrity Check) 기법은 주기적인 무결성 검사(Integrity Check)로 인해 컴퓨터 시스템에 감염된 알려지지 않은 악성 코드를 탐지할 수 있는 장점이 있는 반면에 이러한 장점이 오히려 단점도 된다.
이미 컴퓨터 시스템이 악성 코드에 감염이 되어 감염 피해를 받고 난 이후 임으로 조기 대응이 전혀 불가능하다는 것이다. 특히나 데이터베이스(Database)와 같이 중요한 시스템이 감염 피해를 입게 되었다면 복구에 상당히 많은 시간과 노력을 유발하게 된다.
- 행위 차단 기법 (Behavior Block)
일반적으로 행위 기반 탐지 기법(Behavior Detection)이라고 이야기하는 것은 대부분이 이 행위 차단(Behavior Block) 기법이 발전한 형태로 볼 수 있다. 그리고 에뮬레이터(Emulator) 또는 샌드박스(Sandbox)와도 다른데 이 행위 기반 탐지 기법(Behavior Detection)은 에뮬레이터(Emulator)처럼 컴퓨터 시스템 내에 가상의 공간을 구성한다던가 샌드박스(Sandbox)처럼 컴퓨터 시스템과 실행 파일(Executable File)의 중간에서 리턴값 조작 등을 하지는 않는다.
행위 차단(Behavior Block) 기법은 단순하게 컴퓨터 시스템에서 발생하는 모든 행위들을 모니터링하고만 있을 뿐이다. 그러나 이 모니터링 과정에서 악성 코드와 유사한 행위가 발생하게 되면 이 행위를 유발한 실행 파일(Executable File)이 어떠한 것인지를 추적하여 해당 실행 파일(Executable File)이 더 이상 진행을 하지 못하도록 차단시킨 이후 컴퓨터 시스템 사용자에게 조치를 할 수 있는 경고창을 발생시킨다.
만약 사용자가 해당 실행 파일(Executable File)이 정상 파일이라면 그 이후의 행위를 지속적으로 수행할 수 있도록 진행시키게 된다. 그러나 반대로 사용자가 악성 코드로 의심되는 파일일 경우에는 해당 실행 파일(Executable File)이 더 이상 시스템에서 실행되지 못하도록 강제 종료 시켜 버릴 수가 있다.
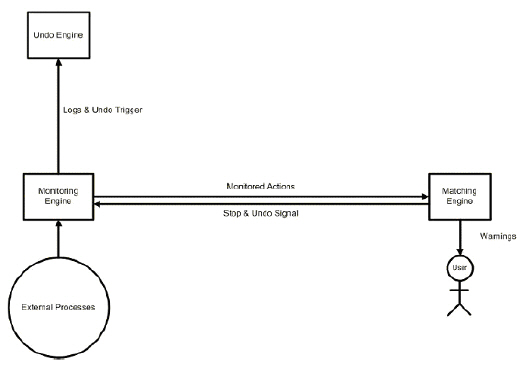
그렇다면 이러한 행위 차단(Behavior Block) 기법의 대표적인 소프트웨어 중 하나인 게이트키퍼(GateKeeper)를 통해서 자세히 살펴보도록 하자. [그림 10]은 게이트키퍼(GateKeeper) 프로그램의 기본 구조를 도식화한 것이다.
위 [그림 10]과 같이 게이트키퍼(GateKeeper)는 모니터링 엔진(Monitoring Engine)에 의해서 현재 시스템에서 실행 중인 모든 파일들에 대해서 감시를 하게 된다.
이 과정에서 새로운 실행 파일(Executable File)이 실행되면 이 모니터링 엔진(Monitoring Engine)은 해당 파일의 처음 시작부터 감시를 진행하며 해당 실행 파일(Executable File)이 어떠한 순서로 실행이 되는지를 모두 추적한 후 복귀 엔진(Undo Engine)을 통하여 로그(Log)를 모두 남기게 된다.
그리고는 해당 실행 파일(Executable File)의 추적을 통하여 생성한 로그(Log)를 비교 엔진(Matching Engine)을 통하여 해당 실행 파일(Executable File)이 악성 코드의 실행 형태와 얼마나 유사한 행위를 유발하고 있는지를 측정하게 된다.
여기에서 만약 해당 실행 파일(Executable File)이 악성 코드로 판단되면 시스템 사용자에게 게이트키퍼(GateKeeper)는 현재 실행 중인 파일이 악성 코드로 판단된다는 경고를 유발하게 된다.
시스템 사용자는 해당 판단을 근거로 실행 차단을 선택하게 될 경우, 복귀 엔진(Undo Engine)은 자신이 기록한 해당 실행 파일(Executable File)의 로그(Log)들 분석하여 실행된 순서를 역으로 시스템에 대한 복구 작업을 수행하게 된다.
이 복구 작업을 통하여 게이트키퍼(GateKeeper)는 해당 실행 파일(Executable File)에 의해서 발생한 시스템 변화에 대해서 실행되기 전의 상태로 복구를 할 수가 있게 된다.
이러한 형태의 행위 차단(Behavior Block) 기법은 알려지지 않은 악성 코드가 실행될 경우에는 이를 사용자에게 알려주고 차단할 수가 있다는 면을 장점으로 볼 수가 있다.
그러나 오탐(False Positive)으로 인하여 너무나도 자주 경고 창이 발생된다면 이는 오히려 시스템 사용자에게 어떠한 것이 알려지지 않은 악성 코드인지 정확한 판단을 하기가 어려워지게 된다.
그리고 이러한 경고 창으로 인하여 오히려 시스템 사용자에게 정상적인 시스템 사용이 방해될 정도의 불편함을 유발 할 수도 있게 된다. 그리고 행위 차단(Behavior Block) 기법 역시 알려지지 않은 악성 코드가 실행이 될 경우 이를 탐지해야 되는 윈도우 응용 프로그램임으로 앞서 설명한 샌드박스(Sandbox)와 동일한 문제점을 안고 있다.
즉, 행위 차단(Behavior Block) 기법이 적용된 시스템이 악성 코드의 실행을 정상적으로 컨트롤을 하지 못하게 될 경우에는 시스템이 악성 코드에 감염이 되는 치명적인 문제를 유발 할 수도 있다는 것이다.
성숙한 보안 의식의 필요성
우리 사회는 이제 컴퓨터 시스템이 없으면 정상적인 사회 생활을 할 수가 없을 수준에 이르렀다. 병원에서는 환자의 진료 기록과 은행에서는 고객의 신용정보 그리고 통장 관리 등 다양한 목적으로 사용되고 있는 컴퓨터 시스템을 보호하기 위해서 안티 바이러스(Anti-Virus) 업체에서는 다양한 알려지지 않은 악성코드 탐지 기법들을 연구하고 개발하고 있다고 이야기 하였다.
그러나 이러한 다양한 기법들이 개발되더라도 가장 중요한 부분은 바로 컴퓨터 시스템을 사용하고 있는 컴퓨터 사용자의 보안 의식이라고 할 수 있다.
일반적으로 정보 보호(Information Security)에서는 보안에서 가장 취약한 부분은 컴퓨터 시스템이나 응용 프로그램이 아니라 보안 의식 없이 컴퓨터 시스템을 사용하는 컴퓨터 사용자라고 정의하고 있다.
이렇게 주용한 성숙한 보안 의식은 복잡하고 어려운 것이 아니라 자신이 자주 사용하는 컴퓨터 시스템에는 안티 바이러스(Anti-Virus) 소프트웨어를 설치하고 사용하는 운영체제의 주기적인 보안 패치(Security Patch)를 확인하고 설치하는 등 악성 코드에 감염이 될만한 요소들을 사전에 자신의 컴퓨터 시스템에서 제거를 하여 보호를 하는 것에서부터 출발한다고 할 수가 있다.
이렇게 가볍게 출발할 수 있는 성숙한 보안 의식이 바로 알려지지 않은 악성 코드를 사전에 탐지 할 수 있는 가장 훌륭한 방안이 아닐까 하는 생각을 해본다.[Ahn]
참고 문헌
The Art of Computer Virus Research and Defense – Peter Szor (2005)
Computer Viruses and Malware – John Aycock (2006)
Heuristic Engines – Francisco Fernandez (Virus Bulletin 2001 Paper)
Full Potential of Dynamic Binary Translation for AV Emulation Engine – Ji Yan Wu (Virus Bulletin 2006 Paper)
Sandbox Technology inside AV Scanners – Kurt Natvig (Virus Bulletin 2001 Paper)
Description of the CWSandbox – Carsten Willems
Heuristic Detection of Viruses within E-mail - Alex Shipp (Virus Bulletin 2001 Paper)
Prevalence of PE packers in e-mail traffic – Maksym Schipka (AVAR 2006 Paper)
Behavior Oriented Detection of Malicious Code at Run-Time – Matthew Evan Wagner (F.I.T 2004 Paper)
Behavioral Classification – Tony Lee & Jigar J. Mody (EICAR 2006 Paper)
Anti-Malware Tools: Intrusion Detection Systems – Martin Overton (EICAR 2005 Paper)
[저자] 안철수연구소 ASEC 장영준 주임연구원
[안철수연구소 2007-03-13]
(1) 악성코드 분석가 입장에서 본 PE 구조
1. 악성코드와 PE(Portable Executable)파일의 조우
PE 파일이라 부르는 형식은 플랫폼에 관계없이 Win32 운영체제 시스템이면 어디든 실행 가능한 프로그램을 뜻한다. PE 파일(*.EXE, *.DLL)의 실행을 위해서는 운영체제에 실행 파일의 정보를 제공할 필요가 있는데, 예를 들면 실행 파일의 기계어 코드 위치, 아이콘 및 그림파일 등의 위치, 해당 파일이 실행될 수 있는 플랫폼의 종류, 운영체제가 파일을 실행 시킬 때 첫 시작 코드의 위치 등 수많은 정보를 제공하여야 한다. 이와 같은 다양한 정보들이 저장된 곳이 PE 파일의 처음에 위치한 PE 헤더 구조체이다.
악성 코드를 분석하여 보면 PE 헤더 구조체에 흥미로운 정보들이 많이 존재하고 있음을 알 수 있다. 악성 코드의 크기를 줄이기 위해 헤더 정보를 속이거나, 바이러스에 감염되어 원본 파일의 헤더가 변경 되기도 한다. 또한 특정 악성코드만의 고유한 정보가 숨어 있기도 하며, 일반 정상파일에서는 있을 수 없는 값들이 들어 있기도 하다.
2. 현재의 악성코드가 DOS 시절의 헤더를 이용한다?
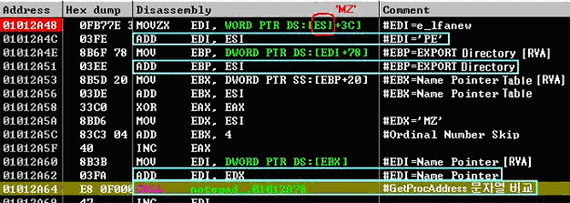
PE 파일은 IMAGE_DOS_HEADER 구조체로 시작한다. 이는 DOS 시절에 사용되던 실행 파일의 헤더로서 실행 파일이 DOS에서 실행 되었을 때 DOS 운영체제에 알려줘야 할 정보들이 담겨 있다. 다음은 IMAGE_DOS_HEADER 구조체이다.
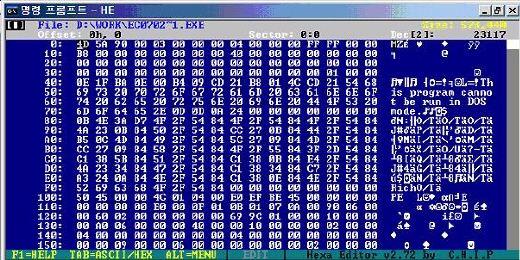
그러나, 이것은 DOS 운영체제를 위해 제공하는 정보들이기 때문에 현재 Windows 환경에서는 필요치 않다. 대다수의 필드들은 무시되며 e_magic 및 e_lfanew 필드만이 유용한 정보가 된다. e_magic 필드는 IMAGE_DOS_HEADER의 시작을 나타내는 것으로 항상 'MZ'라는 문자열로 시작을 한다. 그리고 e_lfanew 필드는 IMAGE_DOS_HEADER 다음에 나오는 헤더 파일의 오프셋 값을 가지고 있다. 그 외의 필드들은 Windows에서 파일을 실행시켰을 때 이용되지 않는다. 다음 [그림 3-1]은 일반적인 실행 파일의 IMAGE_DOS_HEADER의 값이다.

이 위의 값들은 만일 DOS Mode 실행 시 Dos Stub 실행을 목적으로 지정된 값들로 이 헤더 뒤에 따르는 문자열 "This program cannot be run in DOS mode"을 출력해 주기 위해 지정된 값들이다. Dos가 아닌 Windows 모드에서 실행 시켰을 경우에는 이용되지 않는다. 그러나 몇몇 악성코드를 분석하다 보면 실제 사용되지 않는 필드 값들이 악성코드에 의해 사용 되고 있는 흥미로운 사실을 발견할 수 있다. 다음 [그림 3-2]는 악성코드에서 많이 사용되는 실행압축 방식의 하나인 Upack의 IMAGE_DOS_HEADER 부분이다.

앞서 설명한 IMAGE_DOS_HEADER 와는 확연한 차이를 보인다. e_magic 및 e_lfanew 필드 이외의 값들이 'KERNEL32.DLL', 'LoadLibraryA', 'GetProcAddress' 등의 문자열로 채워진 것을 확인 할 수 있다. 이들 문자열들은 동적링크를 위한 함수 호출에 필요한 문자열들로 실행압축인 Upack에서 필요한 라이브러리 함수(DLL)들을 가져다 쓰는 루틴을 위해 존재한다. 여기서는 범용 실행압축 모듈인 Upack을 통해 실제 이용되지 않는 필드들을 활용하는 사례를 다루었지만, 악성코드들 역시 필요한 정보들의 보관을 위해 IMAGE_DOS_HEADER의 빈 공간을 적절히 이용하고 있다.
3. e_lfanew 필드가 IMAGE_DOS_HEADER 범위 안을 가리키고 있다?
IMAGE_DOS_HEADER의 e_lfanew 필드는 다음에 올 헤더 위치의 파일 오프셋을 가리키고 있다. 즉, 실제 PE 파일의 시작이라고 할 수 있는 IMAGE_NT_HEADER의 시작 오프셋 값을 가지고 있다. 다음 [그림 3-3]은 일반적인 실행 파일의 e_lfanew 필드의 값인 0x0000000E 위치의 값을 보여준다.

위 그림과 같이 일반적인 실행 파일은 다음에 올 헤더 위치의 파일 오프셋을 가리키고 있다. 0x000000E0 위치에 있는 헤더는 IMAGE_NT_HEADER로써 다음과 같은 구조체로 정의가 되어 있다.
첫 필드인 Signature는 PE 헤더의 시작을 알리는 값으로 'PE'라는 문자열이 들어가게 된다. 그렇기 때문에 IMAGE_DOS_HEADER의 e_lfanew 필드가 가리키는 위치를 가보면 'PE\0\0'과 같은 문자열이 나타나게 된다. IMAGE_FILE_HEADER와 IMAGE_OPTIONAL_HEADER32는 PE 구조체의 세부적인 값들로 지정된 구조체이다. 그럼 e_lfanew 필드는 언제나 자신보다 뒤에 있는 영역을 가리키고 있는 것일까? 일반적인 실행파일의 경우 그렇다고 할 수 있다. 그러나 몇몇 악성코드들에서는 다음 [그림 3-4]와 같은 모습이 보여지기도 한다.

일반적인 실행파일과 다르게 IMAGE_DOS_HEADER의 e_lfanew 필드가 자신보다 앞의 영역을 가리키고 있다. 이와 같이 다소 일반적이지 않은 형태로 구조체가 정의 되더라도 각 필드에 맞는 값들이 채워진다면 운영체제가 파일을 읽어 들여서 실행하는 것에는 문제가 되지 않는다. 특히 IMAGE_DOS_HEADER의 첫 필드와 마지막 필드를 제외하고는 현재 이용되지 않기 때문에 전혀 문제가 되지 않는다. 단, IMAGE_NT_HEADER 구조체의 시작이 앞으로 이동하게 되면 e_lfanew 필드 값이 PE 헤더 값과 겹치게 되므로, e_lfanew 필드 값과 매칭되는 PE 헤더의 값(BaseOfData)에 문제가 없어야만 한다.
다음 [그림 3-5]를 살펴보면 IMAGE_DOS_HEADER의 e_lfanew 필드는 파일 오프셋으로 0x00000010을 가리키고 있다. 그리고 IMAGE_NT_HEADER의 앞부분에 위치한 이용되지 않는 IMAGE_DOS_HEADER의 영역에 'KERNEL32.DLL' 문자열을 숨겨 두었다. IMAGE_NT_HEADER를 보면 PE 헤더의 시작 뒤를 보면 파일 오프셋 0x0000002A 부분부터 'LoadLibraryA' 문자열이 있는 것을 확인할 수 있다.

해당 영역은 IMAGE_NT_HEADER에 멤버로 등록된 구조체인 IMAGE_OPTIONAL_HEADER의 영역으로 각 대칭되는 필드는 다음 그림 [3-6]과 같다.
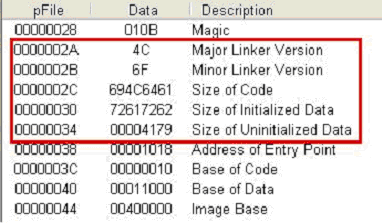
Major Linker Version, Minor Linker Version, SizeOfCode, SizeOfInitializedData, SizeOfUninitializedData의 값이 된다. Major 및 Minor Linker Version 필드는 실행파일을 만든 링커의 버전을 담고 있으며, SizeOfCode 필드는 모든 코드 섹션들의 사이즈를 합한 크기이다. SizeOfInitializedData 필드는 코드 섹션을 제외한 초기화된 데이터 섹션의 전체 크기를 나타내며, SizeOfUninitializedData 필드는 초기화되지 않은 데이터 섹션의 바이트 수를 나타낸다. 일반적인 실행파일의 경우 이러한 값들은 거의 쓰이지 않는다.
4. 다른 컴퓨터의 정상적인 실행 파일과 내 컴퓨터의 정상적인 실행 파일이 다르다?
일반적으로 같은 플랫폼에서의 같은 실행 파일의 경우 직접 링커를 통해 실행 파일을 만들지 않는 이상(즉, 일반적으로 제공되는 어플리케이션을 설치했을 경우에는) 같은 속성을 가지게 된다. 그러나 이 실행 파일 헤더의 특정 몇몇 부분이 다를 경우에는 실행 파일이 감염 되었음을 의심해 볼 수 있다. [그림 3-7]과 [그림 3-8]에서 진단명 Tufic.C에 감염 전후의 explorer.exe 파일의 차이를 확인해볼 수 있다.
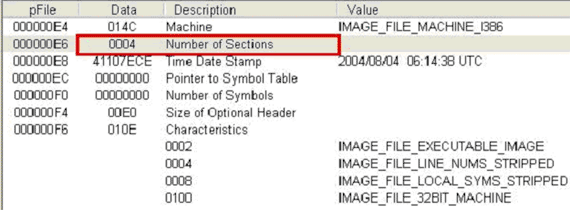
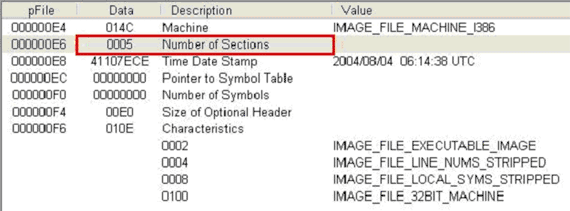
[그림 3-7]은 Tufic.C 감염되기 이전의 IMAGE_NT_HEADER에 속한 IMAGE_FILE_HEADER의 값이며, [그림 3-8]은 감염된 이후의 모습이다. 박스안의 NumberOfSections 필드를 살펴보면 감염된 이후에 값이 1만큼 증가한 것을 확인 할 수 있다. Tufic.C는 원본 파일의 맨 뒤에 바이러스를 첨가 시키는 Appending 바이러스의 한 유형으로 바이러스를 추가할 부분을 만들기 위해 섹션의 수를 하나 증가시켜 놓은 것이다.
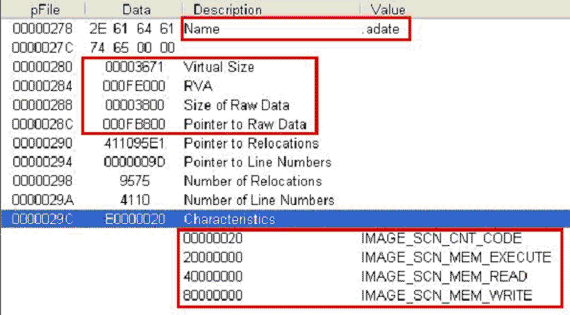
[그림 3-9]는 추가된 섹션 헤더의 모습이다. 여기에서 상당히 많은 악성코드 정보를 얻을 수 있으며, 이러한 정보는 악성코드 분석에 큰 도움을 준다. 우선 섹션의 이름은 .adate임을 알 수 있다. Tufic.C와 같이 바이러스 감염 시 섹션 이름을 특정 문자열로 주게되면, 바이러스 감염여부에 대한 기초적인 판단 정보가 되기도 한다. VirtualSize는 감염 파일이 운영체제에 의해 로드 되었을 때, 이 섹션의 이미지상의 크기를 나타내어 준다.
이것은 바이러스 코드의 길이를 짐작 할 수 있다. RVA는 실행 파일이 운영체제에 의해 로드 되었을 때 메모리상의 위치 정보이며, 감염 파일을 분석할 때 바이러스 코드를 확인 할 수 있다. SizeOfRawData는 파일상에서 섹션의 크기에 대해 알 수 있으며, 치료할 때 사용 된다. PointerToRawData는 파일상의 섹션 위치를 알 수 있으며 이것 또한 치료할 때 사용 된다. Characteristics은 해당 섹션의 속성을 나타내는 플래그의 집합이다.
바이러스가 생성한 섹션의 플래그는 IMAGE_SCN_CNT_CODE, _EXECUTE, _READ, _WRITE 등의 속성이 지정되어 있으며 각각은 '코드를 포함하고 있다', '실행 가능한 섹션이다', '읽기 가능 섹션이다', '쓰기 가능 섹션이다'는 것을 의미한다. [그림 3-10]에서와 같이 섹션 정보 이외에 수정되는 것이 더 있는지 확인을 해 보면 중간 부분에서와 같이 몇 개의 필드가 수정된 것을 확인할 수 있다.
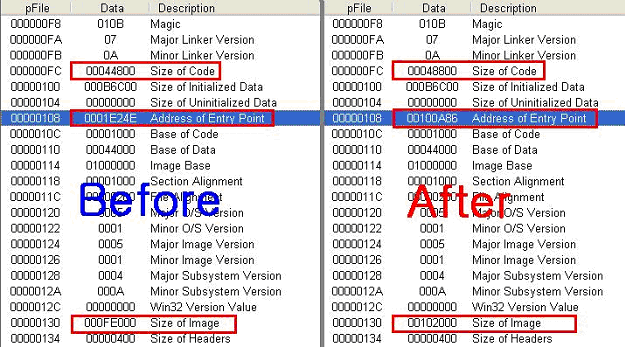
IMAGE_NT_HEADER에 속해 있는 IMAGE_OPTIONAL_HEADER32 구조체의 필드 값들이다. 왼쪽이 감염 이전의 explorer.exe 파일이며, 오른쪽이 감염 이후의 explorer.exe 파일이다. 감염 전/후를 비교해 보면, 세 부분이 바뀐 것을 확인 할 수 있는데, 첫 번째 SizeOfCode는 앞서 설명과 같이 모든 코드 섹션의 사이즈를 합한 크기이며 그 크기가 증가한 것을 확인 할 수 있다. 또한 맨 마지막의 SizeOfImage는 운영체제가 이 실행 파일을 로드할 때 확보/예약해야 할 메모리상의 크기를 가리킨다. 이 또한 SizeOfCode가 증가한 크기만큼 증가한 것을 확인 할 수 있다.
중요한 것은 AddressOfEntryPoint 인데 이 부분은 운영체제가 실행 파일을 로드 했을 때, 이 실행 파일의 코드 시작점을 나타낸다. Tufic.C에 감염 되었을 경우에는 이와 같이 코드 진입점이 변경되며 변경된 코드 진입점은 바이러스의 시작 주소를 가리키게 된다. 이것은 바이러스 분석에 결정적 자료가 된다.(물론 이처럼 AddressOfEntryPoint 필드를 변경하지 않고, 실제 시작 코드를 변경하는 바이러스들도 존재한다.) 변경된 원본 AddressOfEntryPoint는 바이러스가 나중에 원본 파일을 정상 실행 시키기 위해서 임의의 위치에 백업을 해 둔다.
5. Import Address Table 정보를 이용한 악성코드 분석
DLL(Dynamic Link Library)은 서로 다른 프로그램이 실행된 후 공통적으로 사용하는 함수들을 하나로 묶어두고 이를 필요로 할 때 동적으로 링크하여 사용하는 공유 라이브러리 파일이다. 각각의 프로그램에서 하나의 함수를 공통적으로 사용하게 되므로 메모리가 절약되고, 주 프로그램과 함께 컴파일 되는 정적 링크에 비해 상대적으로 작은 사이즈를 가지는 잇점이 있다.
최대한 간략하게 만들어야 하는 악성코드 역시 필요한 함수를 동적 링크 하는 것이 일반적이므로, 함께 링크되는 DLL 함수 정보를 살펴보면 악성코드가 의도하는 목적을 유추할 수 있다. PE 구조에서 해당 정보를 보관하고 있는 Import Address Table을 찾아가 보기로 한다.
1) PE 파일의 시작(e_magic)에서 0x3C 만큼 이동하면 IMAGE_NT_HEADERS 시작 오프셋 값(e_lfanew)을 찾을 수 있다
2) IMAGE_NT_HEADERS 시작 오프셋(Signature)에서 0x80 만큼 이동한 지점이 Import Directory RVA 구조체 정보이다. 구조체 엔트리에 대한 의미는 WinNT.H 파일에 다음과 같이 정의되어 있다.
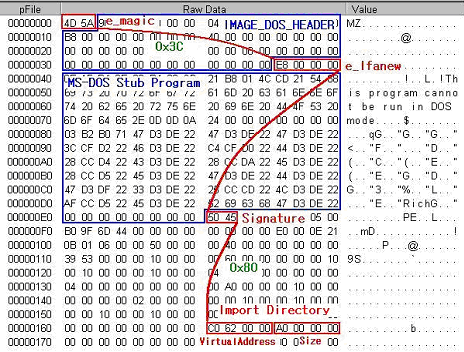
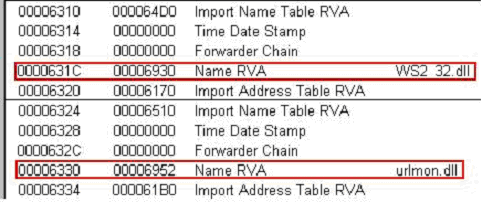
3) Import Directory RVA에 대한 FileOffset으로 이동하면 동적으로 링크하는 DLL 파일들의 구조체(IMAGE_IMPORT_DESCRIPTOR)정보를 확인할 수 있다. 다음은 Win-Trojan/Backdoor.40960.B 에서 동적으로 링크하는 DLL 및 그에 따른 함수(Import Address Table) 정보를 일부 발췌한 것이며, 이를 통해 해당 악성코드는 URL 접속 및 정보유출, 불특정 파일 다운로드 등의 증상을 유추해 볼 수 있겠다.
● urlmon.dll: Internet Explorer의 구성요소로, 웹사이트에서 반환된 URL과 정보를 처리한다
● WS2_32.dll: Windows Socket API, WSAStartup 함수를 통해 DLL을 로딩하여 사용한다

6. Import Address Table 정보를 은닉한 악성코드 분석
레지스트리 및 파일 I/O, 소켓연결, 프로세스 관련 함수 호출은 악성코드들이 즐겨 사용하며,이를 통하여 안티바이러스 프로그램 및 분석가들도 악성 여부를 판단하는 기초 자료로 사용한다.
이러한 특성을 인지한 악성코드 제작자들은 치료백신 업데이트 및 분석 지연을 목적으로 DLL 정보 및 호출함수 정보를 은닉하게 되는데 실행압축(Packer), 암호화(Encrypt)등을 사용하는 것이 일반적이며, 일부 악성코드는 PE 구조체의 Import Address Table 정보를 메인루틴 에서 생성하기도 한다.
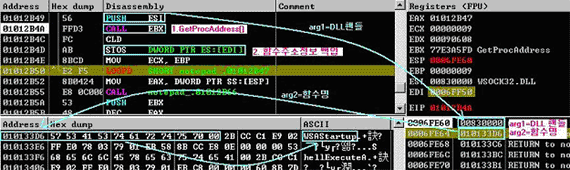
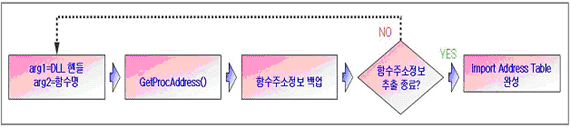
1) GetProcAddress() 함수주소 획득
호출 함수들의 주소정보 획득을 위해서 DLL 핸들, 함수명을 인자값으로 GetProcAddress()를 호출하며, GetProcAddress() 함수에 대한 주소정보는 메인루틴 상의 kernel32.dll 에서 획득한다. 다음은 Win32/MaDang 에서 GetProcAddress() 함수 주소를 획득하는 과정을 보여준다.

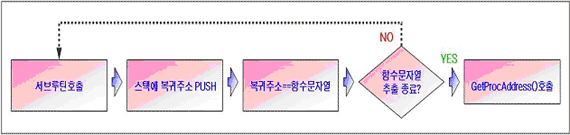
2) 함수명 추출을 위한 서브루틴 호출
LoadLibrary()를 통해 DLL핸들이 확보되면, GetProcAddress() 인자값으로 사용할 함수명을 추출해야 하는데, Win32/MaDang 에서는 다소 변칙적인 함수호출 과정을 이용한다. 일반적인 함수 호출은 서브루틴이 호출되면 복귀주소(Return Address)가 스택에 쌓이고(PUSH) 서브루틴 종료시 복귀주소를 스택에서 꺼내어(POP) 메인루틴으로 복귀하는 과정을 밟는다. 다음은 Win32/MaDang 에서 위와 같은 함수호출 과정으로 스택에 쌓인 값이 복귀주소를 가리키지 않고 함수명을 가리킬 수 있음을 보여준다.
3) 호출 함수들의 주소정보 획득
다소 변칙적인 함수호출 과정을 통해 필요한 함수명이 스택에 저장되었고 DLL핸들 또한 확보되었다. 최종적으로 GetProcAddress() 함수 호출을 통해 메인루틴에서 사용될 함수들의 주소정보를 모두 획득하면 Import Address Table 이 완성된다.
7. PE(Portable Executable) 구조체와 악성 코드 분석가의 조우
악성코드를 분석하다 보면 이 이외에도 많은 흥미로운 것들을 발견할 수 있다. 그러나 앞에서 언급을 했듯이 모든 악성코드들이 이러한 특성들을 가지고 있는 것은 아니며, 정상 파일은 이러한 특성을 가지지 않는 것은 아니다. 다만 악성코드들에서 발생 빈도가 더 높을 뿐이다.
이러한 정보들은 악성코드의 악의적인 동작들과는 관계가 없는 것들은 많지만, 악성코드를 분석하고 악성/정상을 판단하는 것에 결정적인 힌트가 되어 주기도 한다. 또한 각 악성코드만의 PE 헤더 특성을 악성코드 진단에 이용할 수 있으며 바이러스와 같은 경우에는 정상파일을 감염시켜 PE 헤더의 내용을 바꾸는 동작을 수행할 가능성이 높기 때문에 치료함수를 제작하기 위해서 이러한 PE 헤더의 바뀐 부분에 대한 파악이 중요하다. 그러므로 PE 구조체와 악성코드 분석은 떼어낼래야 뗄 수 없는 관계이다.
[출처] 안철수연구소 ASEC

|