|
Linux와 Windows에서의 고성능 프로그래밍 기술 |
난이도 : 초급 Edward G. Bradford 박사, 수석 Programmer, IBM 2001 년 10 월 01 일 Ed는 OS 프로그래밍 인터페이스에 대한 연구를 시작한다. 그 첫 번째 대상은 pipe 이다. 연구 대상 OS에 최근에 배포된 Windows XP가 추가되었다. 이 글에서 Ed는 Windows 2000 Advanced Server (Service Pack 2 설치), Linux (Red Hat 7.1), Windows XP professional에서 pipe를 실행한다. 두 개의 Windows 버전을 실험해야 하기 때문에 앞으로 사용하게 될 용어에 대해 설명을 하겠다. Windows 2000과 Windows XP를 구별 할 필요가 없을 때에는 "Windows"라고 하겠다. 구별이 필요할 때에는, "Windows 2000" 또는 "Windows XP"라고 각각 명기하도록 하겠다. pipe는 Windows와 Linux (UNIX)에서 실행하는 프로세스간 통신 메커니즘이다. pipe는 원래 UNIX의 Bell Laboratories version에 나타났고 후에 모든 UNIX와 Linux에 쓰이게 되었다. pipe는 정상적인 IO 인터페이스를 통해 액세스 된 바이트 스트림이다. UNIX와 Linux 같은 경우, IO 호출은 Windows pipe는 Linux pipe 보다 더욱 복잡하다. Windows는 named와 unnamed pipe를 지원한다. unnamed는 인터페이스가 이름을 밝히지 않는 곳의 단순한 named pipe 이다. Windows는 pipe 에 비동기식 IO를 지원한다. 싱글 쓰레드가 pipe로의 IO 호출을 막지않는다. 다른 IO 인터페이스틑 비동기식 IO 기능을 사용할 때 필요하다. Windows pipe는 byte type과 message type이 있다. byte-type pipe는 UNIX pipe와 유사하고 byte 스트림을 지원한다.이 글에서는 message-type pipe는 연구 대상에서 제외할 것이다. Windows pipe는
anyname 부분만 지정될 수 있다. Windows pipe를 사용하기 위해서, 이것은 하나의 API에 의해 만들어져야 한다. 그리고 또 다른 API에 의해 열려야 한다. 다음 예제 코드는 이것이 어떻게 수행되는지 보여준다. Windows named pipe
첫 번째 실행 라인에서 숫자 24는 시험용으로 결정되었다. Platform SDK에서 이것에 관한 어떤 언급도 찾을 수 없었다. 이것이 존재하지 않으면 프로그램은 작동하지 않는다. 분명한 것은 pipe는 쓰기에 24 바이트 헤더를 필요로 한다. Linux pipe는 작성하고 사용하기가 훨씬 간단하다. 파라미터도 더 적다. Windows와 같은 pipe 생성 태스크를 수행하기 위해서는, Linux와 UNIX는 다음과 같이 한다: Linux named pipe 만들기
Linux pipe는 블록킹(blocking)하기 전에 쓰기 사이즈에 대한 제한이 있다. 각 파이프에 할당된 커널 레벨 버퍼는 정확히 4096 바이트이다. reader가 pipe를 비우면 4K 이상 쓰기는 막힌다. 실제로 이것은 많은 제한이 아니다. 왜냐하면 읽기와 쓰기는 다른 쓰레드에서 수행되기 때문이다. 나는 OS pipe 코드가 얼마나 빠르게 실행되는지 시험하기 위해서 프로그램을 작성했다. (pipespeed2.cpp). 이것은 pipe를 만들고 싱글 쓰레드 안에 있는 모든 데이터를 쓰고 읽는다. Linux는 단지 4K 쓰기를 지원하기 때문에 writer가 막기 전에 테스트는 4K 블록 사이즈에서 멈춘다. 숫자를 만들어냈던 bash 쉘 스크립트는 간단했다: 테스트 결과를 나타내는 bash 쉘 파일
각 실행의 아웃풋은 파일에 저장되고 Microsoft Excel로 쉽게 임포트된 텍스트 파일을 만들기 위해 텍스트 에디터로 편집된다. 이 글의 프로그램들은 다음의 도구를 이용하여 컴파일 된다:
그리고
그림 1은 Linux 2.4.2 커널 (Red Hat 7.1) 결과이다. 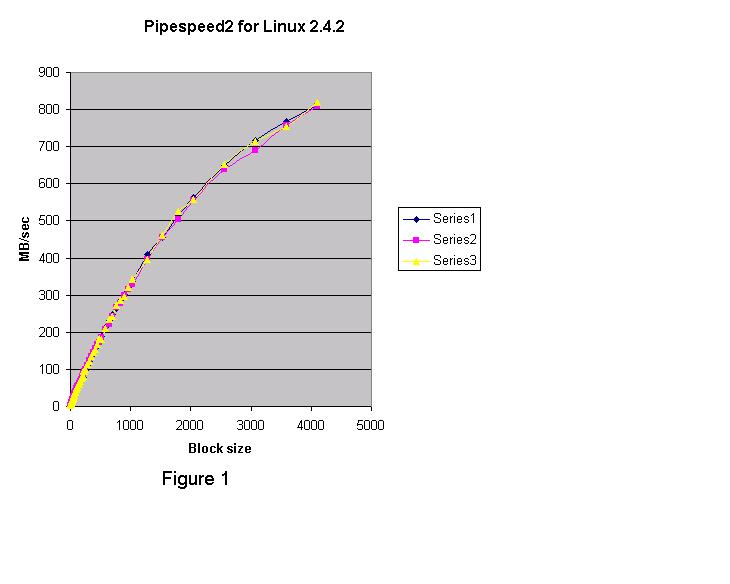 그림 2는 Windows 2000 Advanced Server에서 실행하기 위해 컴파일 된 같은 프로그램이다. 중요하지 않은 서비스는 작동하지 않는다. 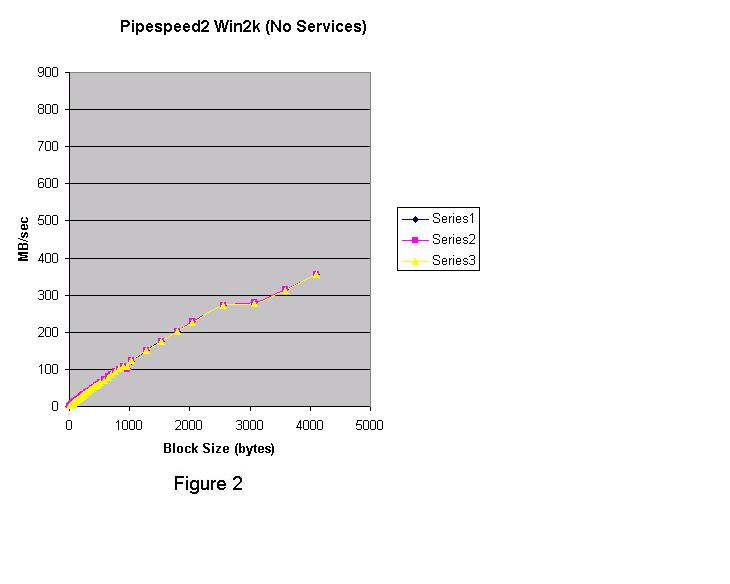 그림 3은 Windows XP의 결과이다. 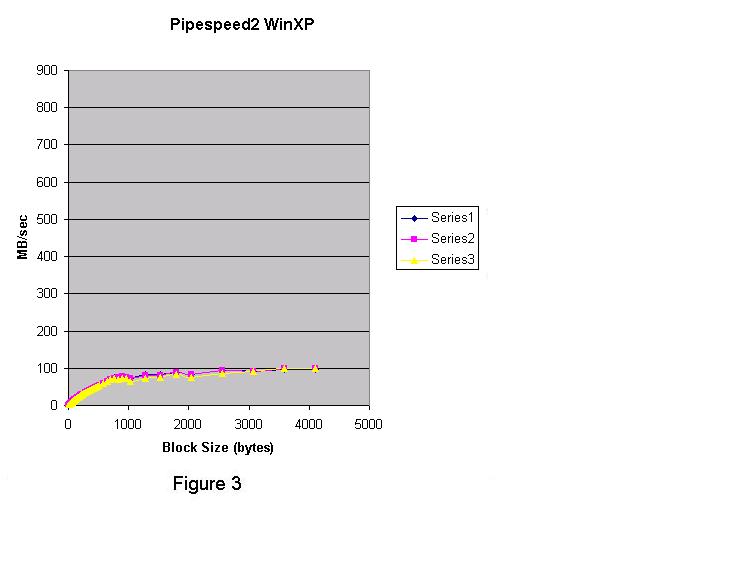 각각의 테스트 실행은 세개의 시리즈로 구성되어있다. 그래픽에서, Linux pipe는 Windows 2000 named pipe보다 훨씬 빠르다. Windows XP named pipe는 Windows 2000 named pipe보다 훨씬 느리다. Windows XP Professional는 평가판(evaluation" version) 이다. Windows 2000 그래프는 블록 사이즈가 4K 이상으로 증가한다면 더욱 향상될수 있다는 것을 보여준다. 4K보다 큰 블록 사이즈를 테스트 하기 위해서 강화된 버전의 pipespeed2.cpp 프로그램이 작성되었다. 새로운 프로그램은 두 번째 쓰레드를 만든다. 첫 번째 쓰레드는 데이터를 작성하고 두 번째 쓰레드는 데이터를 읽는다. 첫 번째 프로그램의 목적은 콘텍스트 변환 오버헤드 없이 pipe 지원의 코드 경로와 관련된 오버헤드를 이해하는 것이다. pipespeed2.cpp의 강화 버전은 pipespeed2t.cpp라고 한다. 두 개의 쓰레드는 모든 데이터를 전송하기 위해 앞 뒤로 스위치를 context 할 것이다. 따라서 두 번째 프로그램은 첫 번째에서 빠진 콘텍스트 변환에 대한 추가 오버헤드를 가지고 있다. 모든 데이터가 전송되고 두 번째 쓰레드가 적절히 종료된 후에 타이밍은 멈춘다. 그림 4, 5, 6은 Linux, Windows 2000, Windows XP를 각각 보여준다. Windows XP는 named pipe 기능에서 심각한 퍼포먼스 저하라는 결과를 나타냈다. 반면 Linux는 Windows 2000 보다 훨씬 나은 성능을 보여주었고, Windows 2000은 Windows XP보다 나았다. 그림 4 는 Linux 2.4.2 커널에서 실행한 pipespeed2t.cpp의 쓰레디드 버전의 결과이다. 피크 (peak) IO 속도는 약 700 MB/sec 이다. 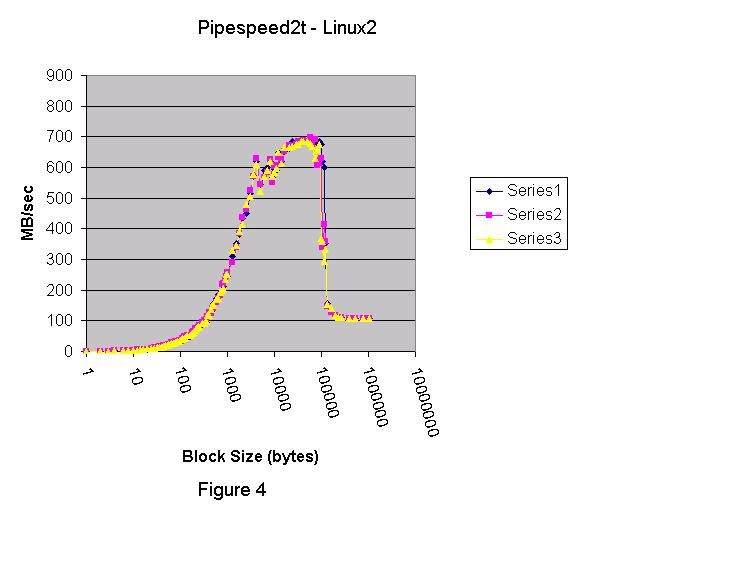 그림 5는 Windows 2000의 쓰레디드 결과이다. 피크(peak) IO 속도는 500 MB/sec에 가깝다. 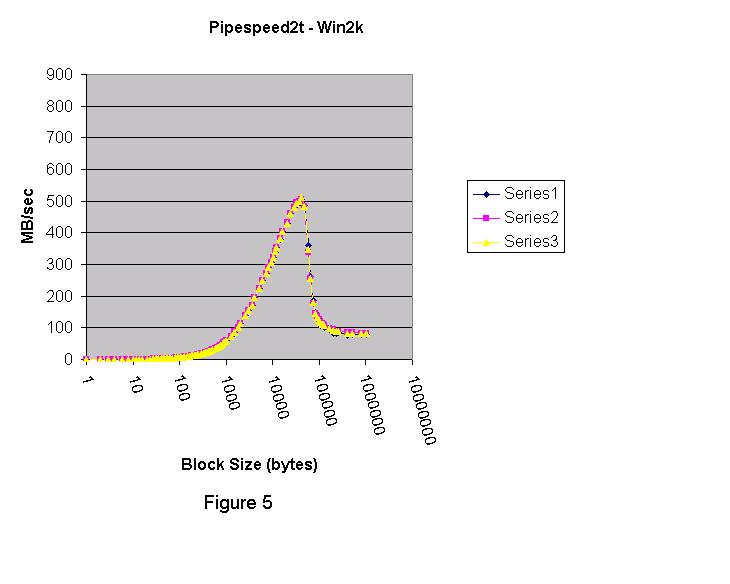 두 개의 그래프 모두 같은 모습이지만 Linux는 매우 큰 블록 사이즈에 대해 100 MB/sec 속도로 안정된 상태에 도달했다. Windows 2000도 큰 블록 사이즈에 안정된 상태에 도달했지만, 겨우 80 MB/sec 이다. 그림 6은 Windows XP Professional (평가판)의 쓰레디드 결과이다. 피크 IO 속도는 120 MB/sec 이다. 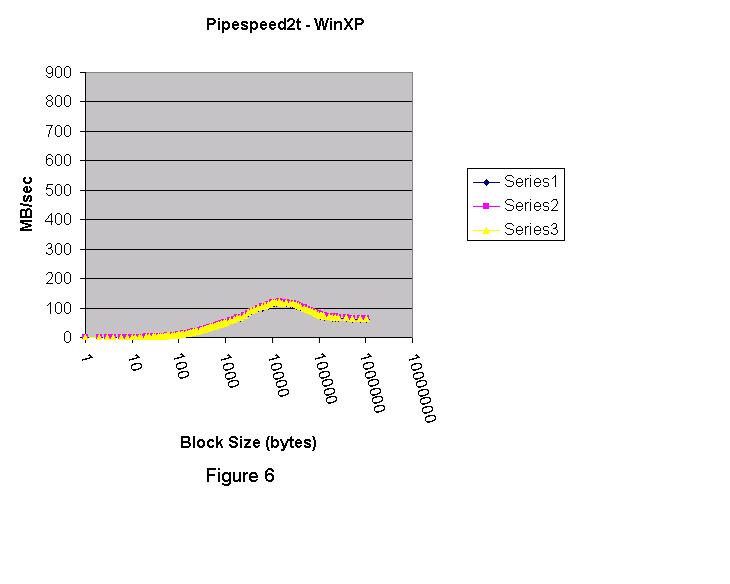 Windows XP는 블록 사이즈에서 실망스러운 결과를 나타낸다. 아마도 Microsoft 전문가라면 discussion forum 에 프로그램과 Windows XP named pipe를 향상시킬 수 있는 유용한 정보를 제공하리라 믿는다. 간단한 프로그램을 통해 얻어진 정보는 프로그램 디자이너, 소프트웨어 아키텍트, 시스템 관리자에게 OS의 기능에 대해 정보를 제공할 수 있다. 간단함만이 "현실적인" 시나리오에 대한 끝없는 논쟁을 없애는 방법이다. "간단함"은 사람들이 프로그램을 작성하는 방식을 말하는 것이다. 이번 경우 어떤 플랫폼의 퍼포먼스를 향상시키기 위해 특별한 어떤 것도 수행하지 않았다. Windows XP의 비참한 퍼포먼스는 당혹스럽다. 데이터 전송에 대한 보다 나은 솔루션으로 소켓을 설명할 수 있다. 다음 칼럼을 통해 다루겠다. Linux 또한 named pipe를 지원한다.나는 Linux에 named pipe를 사용한 다른 프로그램을 작성했다. Linux의 named/unnamed pipe 결과는 구별이 되지 않는다. 첫 번째 테스트는 Linux 와는 다르게 4K 버퍼 사이즈에서 멈췄다. Windows 옹호자들은 Windows named pipe와 관련하여 임의의 버퍼 사이즈가 유리하다고 제안한다. Windows named pipe 버퍼의 임의 사이즈를 나타내기 위해서 임의의 큰 블록 사이즈로 단일 쓰레디드 프로그램을 실행할 수 있었다. Windows에서 pipespeed2.cpp으로 수행하고 256 MB 버퍼 사이즈를 지정했다. Windows 와 Linux에서 pipe를 사용할 때 좋은 프로그래밍 예제로서 두 개의 프로그램을 작성했다. 첫 번째 프로그램은 Linux pipe가 Windows 2000 named pipe보다 훨씬 빠르고, Windows 2000 named pipe는 Windows XP named pipe보다 훨씬 빠르다는 것을 실험을 통해 알 수 있었다.
| ||||||||||||||||||||||||||||||||||
출처 : IBM
